Bab 8 Uji Hipotesis Parameter Dua Populasi Atau Lebih
Capaian Pembelajaran
Setelah mempelajari bab ini, Anda diharapkan mampu memaknai hasil dari pengujian hipotesis parameter dua populasi atau lebih pada suatu kasus STP-7.1
8.1 Konsep Dasar Uji Hipotesis Parameter Dua Populasi Atau Lebih
Pengertian lebih dari satu populasi mengacu pada dua sudut pandang, yaitu:
-
Cakupan populasi yang kita definisikan pada penelitian kita. Jika satu populasi pada penelitian kita adalah “seluruh mahasiswa ITERAâ€, maka dua populasi dapat menjadi “seluruh mahasiswa ITERA†dan “seluruh mahasiswa UIN RILâ€, dan sebagainya.
Akan ada hal yang kita bandingkan dari kedua ataupun seluruh populasi tersebut. Dalam hal ini, kita akan membuktikan bahwa “ada atau tidaknya perbedaan karakteristik dari mahasiswa ITERA dan mahasiswa UIN RILâ€. Perbedaan karakteristik ini dapat berupa parameter tertentu, seperti rata-rata, median, atau proporsi pada dua atau lebih populasi yang diujikan.
Studi Kasus: Batasan Cakupan Sebagai Dasar Penentuan Populasi
Cakupan populasi sangat bergantung pada batasan penelitian. Mari bandingkan dua situasi berikut:
- Situasi 1: Penelitian mengamati mahasiswa di suatu kampus tingkat universitas, misalnya UBL. Dalam hal ini, seluruh mahasiswa UBL adalah satu populasi. Jika kita membandingkannya dengan kampus lain, maka mahasiswa kampus lain tersebut (misalnya UIN RIL) akan menjadi populasi kedua.
- Situasi 2: Penelitian mengamati seluruh mahasiswa di Kota Bandar Lampung. Dalam kasus ini, mahasiswa UBL dan mahasiswa UIN RIL melebur menjadi satu populasi yang sama, yaitu populasi mahasiswa Kota Bandar Lampung. Populasi kedua, misalnya, bisa jadi adalah seluruh mahasiswa di Kota Metro.
Sebagai kesimpulan, penentuan “satu populasi” dapat berubah menyesuaikan lingkup pengamatan yang ditetapkan.
- Waktu pengambilan data. Jika kita mengambil data dari suatu populasi pada dua tahap yang berbeda, misalnya sebelum dan sesudah suatu program, kita dapat menganggap populasi sebelum program sebagai populasi pertama, dan populasi setelah program sebagai populasi kedua.
Studi Kasus: Waktu Pengambilan Data Sebagai Dasar Penentuan Populasi
Batasan populasi juga dapat dibedakan berdasarkan waktu. Sebagai contoh, kita ingin mengevaluasi dampak pembangunan jalan layang (flyover) terhadap waktu tempuh mahasiswa UBL menuju kampus.
- Populasi 1: Waktu tempuh perjalanan seluruh mahasiswa UBL sebelum adanya flyover.
- Populasi 2: Waktu tempuh perjalanan seluruh mahasiswa UBL sesudah flyover tersebut beroperasi.
Meski kelompok subjek yang diamati sama (mahasiswa UBL), perbedaan waktu pengambilan data (sebelum dan sesudah) secara praktis membagi kelompok tersebut menjadi dua populasi.
Sudut pandang pertama juga bisa dibagi lagi menjadi dua populasi berpasangan dan independen. Populasi berpasangan adalah dua populasi yang terikat hubungan satu sama lain secara logis. Misalnya, kita mengambil data suami dan istri dalam suatu kelurahan. Dalam hal tersebut, suami adalah populasi pertama, sementara istri adalah populasi kedua. Sudut pandang kedua juga kita bisa katakan sebagai populasi yang berpasangan.
Dengan demikian, berdasarkan sudut pandangnya, penjelasan uji hipotesis lebih dari satu populasi ini dapat dikelompokkan ke dalam tiga bentuk kasus, yaitu dua populasi tidak berpasangan, dua populasi berpasangan, dan lebih dari dua populasi. Sedangkan berdasarkan statistiknya, kita akan membahas uji hipotesis parameter rata-rata dan proporsi.
8.2 Tahapan Pengujian Hipotesis Parameter Dua Populasi atau Lebih
Secara umum, tahapan pengujian hipotesis parameter dua populasi atau lebih tidak berbeda jauh dengan tahapan pengujian hipotesis parameter satu populasi (subbab 7.6. Perbedaannya hanya terletak pada bentuk hipotesis yang akan diuji dan cara menghitung statistik ujinya.
Untuk menyegarkan ingatan kita, berikut adalah langkah-langkah dalam pengujian hipotesis parameter satu populasi:
- Menyatakan asumsi awal
- Menetapkan hipotesis kosong dan alternatif
- Menetapkan wilayah kritis dari signifikansi
- Mencari nilai titik kritis
- Mencari nilai statistik uji
- Membandingkan nilai statistik uji dan titik kritis
- Menarik kesimpulan dan memaknai hasil pengujian.
Langkah-langkah ini juga akan kita gunakan dalam melakukan uji hipotesis parameter dua populasi atau lebih.
8.3 Uji Hipotesis Parameter Dua Populasi Independen
Dalam subbab ini, kita akan membahas perumusan hipotesis kosong dan alternatif serta perhitungan statistik ujinya, sesuai penjelasan sebelumnya yang mengatakan bahwa dua hal tersebut merupakan hal yang membedakan uji hipotesis parameter dua populasi atau lebih dengan uji hipotesis parameter satu populasi.
8.3.1 Hipotesis Kosong dan Alternatif Uji Hipotesis Parameter Dua Populasi Independen
Pada uji hipotesis dua populasi independen, hanya terdapat dua populasi yang diujikan. Dua populasi ini adalah populasi yang berbeda satu sama lain/tidak saling berkaitan. Dalam uji ini, hipotesis kosong (\(H_0\)) yang menunjukkan kondisi netral dapat dirumuskan sebagai tidak adanya perbedaan parameter antara kedua populasi yang dibandingkan. Bentuk penulisan hipotesis kosong ini dapat dilihat pada Tabel 8.1 berikut.
| Bentuk | Parameter Rata-rata | Parameter Proporsi |
|---|---|---|
| Bentuk Umum | \(H_0: \mu_A = \mu_B\) | \(H_0: P_A = P_B\) |
| Bentuk Selisih | \(H_0: \mu_A - \mu_B = 0\) | \(H_0: P_A - P_B = 0\) |
Dalam Tabel 8.1, kita dapat melihat bahwa hipotesis kosong ini dapat dirumuskan dengan dua bentuk, yaitu bentuk umum dan bentuk selisih. Kedua bentuk ini sebenarnya memiliki arti yang sama, yaitu tidak adanya perbedaan antara kedua populasi yang dibandingkan. Hanya saja, bentuk selisih lebih mudah diterapkan ketika kita hanya berfokus pada perbedaan nilai parameter antara kedua populasi tersebut alih-alih nilai absolut parameter-parameternya.
Sementara itu, hipotesis alternatif (\(H_1\)) menunjukkan kondisi adanya perbedaan antara kedua populasi tersebut — baik perbedaan yang memiliki arah (lebih besar atau lebih kecil), maupun yang tidak memiliki arah (tidak sama dengan). Perhatikan Tabel 8.2 berikut֫.
| Bentuk | Parameter Rata-rata | Parameter Proporsi |
|---|---|---|
| Bentuk Umum |
\(H_1: \mu_A \ne \mu_B\) \(H_1: \mu_A > \mu_B\) \(H_1: \mu_A < \mu_B\) |
\(H_1: P_A \ne P_B\) \(H_1: P_A > P_B\) \(H_1: P_A < P_B\) |
| Bentuk Selisih |
\(H_1: \mu_A - \mu_B \ne 0\) \(H_1: \mu_A - \mu_B > 0\) \(H_1: \mu_A - \mu_B < 0\) |
\(H_1: P_A - P_B \ne 0\) \(H_1: P_A - P_B > 0\) \(H_1: P_A - P_B < 0\) |
8.3.2 Perhitungan Statistik Uji dalam Uji Hipotesis Parameter Dua Populasi Independen
Secara matematis, perhitungan statistik uji pada beda dua rata-rata independen diawali dengan membandingkan selisih rata-rata dari kedua sampel (\(\bar{x}_1 - \bar{x}_2\)) terhadap hipotesis selisih dari kedua rata-rata populasinya (\(\mu_1 - \mu_2\)), untuk kemudian dibagikan dengan standar error-nya.
Untuk parameter rata-rata, statistik uji yang digunakan adalah sebagai berikut:
\[ Z_{hitung} = \frac{(\bar{x}_1 - \bar{x}_2) - (\mu_1 - \mu_2)}{SE_{\bar{x}_1 - \bar{x}_2}} \tag{8.1} \]
Di mana:
- \(\bar{x}_1, \bar{x}_2\) = Rata-rata sampel 1 dan sampel 2
- \(\mu_1, \mu_2\) = Rata-rata populasi 1 dan populasi 2
- \(SE_{\bar{x}_1 - \bar{x}_2}\) = Standar error dari selisih rata-rata sampel 1 dan sampel 2
Perlu diperhatikan bahwa \((\mu_1 - \mu_2)\) pada persamaan (8.1) mencerminkan nilai hipotesis selisih rata-rata kedua populasi. Dalam pengujian hipotesis, nilai tersebut ditetapkan sesuai dengan hipotesis kosong (\(H_0\)). Karena \(H_0\) pada umumnya menyatakan tidak adanya perbedaan antar populasi (yakni \(\mu_1 - \mu_2 = 0\)), maka suku \((\mu_1 - \mu_2)\) ini bernilai nol dan gugur dari perhitungan.
Perhitungan standard error dari selisih rata-rata sampel 1 dan sampel 2 adalah sebagai berikut:
\[ SE_{\bar{x}_1 - \bar{x}_2} = \sqrt{ \frac{s_1^2}{N_1 - 1} + \frac{s_2^2}{N_2 - 1} } \tag{8.2} \]
Di mana:
- \(s_1^2, s_2^2\) = Varians (standar deviasi yang dikuadratkan) dari sampel 1 dan sampel 2
- \(N_1, N_2\) = Jumlah total masing-masing observasi sampel 1 dan sampel 2
Dengan demikian, menggabungkan persamaan (8.1) dan (8.2), perhitungan statistik uji beda dua rata-rata independen menjadi:
\[ Z_{hitung} = \frac{\bar{x}_1 - \bar{x}_2}{\sqrt{ \frac{s_1^2}{N_1 - 1} + \frac{s_2^2}{N_2 - 1} }} \tag{8.3} \]
Di mana:
- \(\bar{x}_1, \bar{x}_2\) = Rata-rata sampel 1 dan sampel 2
- \(s_1^2, s_2^2\) = Varians (standar deviasi yang dikuadratkan) dari sampel 1 dan sampel 2
- \(N_1, N_2\) = Jumlah total masing-masing observasi sampel 1 dan sampel 2
Sementara itu, untuk parameter proporsi, statistik uji untuk beda dua proporsi independen dihitung dengan cara yang mirip dengan beda dua rata-rata, yaitu membandingkan selisih proporsi sampel (\(\hat{p}_1 - \hat{p}_2\)) terhadap nilai nol (karena \(H_0: P_1 - P_2 = 0\)), dikalibrasi dengan standard error-nya:
\[ Z_{hitung} = \frac{\hat{p}_1 - \hat{p}_2}{\sqrt{\hat{p}(1-\hat{p})\left(\dfrac{1}{N_1} + \dfrac{1}{N_2}\right)}} \tag{8.4} \]
Di mana:
- \(\hat{p}_1, \hat{p}_2\) = Proporsi sampel dari populasi 1 dan populasi 2
- \(N_1, N_2\) = Jumlah total observasi sampel populasi 1 dan populasi 2
- \(\hat{p}\) = Proporsi gabungan (pooled proportion), dihitung sebagai:
\[ \hat{p} = \frac{x_1 + x_2}{N_1 + N_2} = \frac{N_1 \hat{p}_1 + N_2 \hat{p}_2}{N_1 + N_2} \tag{8.5} \]
Di mana:
- \(x_1\) dan \(x_2\) adalah jumlah observasi yang memenuhi kategori yang diuji pada masing-masing sampel
- \(N_1\) dan \(N_2\) adalah jumlah observasi sampel 1 dan sampel 2
- \(\hat{p}_1\) dan \(\hat{p}_2\) adalah proporsi sampel 1 dan sampel 2
Perlu dicatat bahwa pada persamaan (8.4), standar error dihitung menggunakan proporsi gabungan (\(\hat{p}\)) — bukan proporsi masing-masing sampel. Ini dilakukan karena, di bawah asumsi \(H_0\) (bahwa kedua proporsi populasi sesungguhnya adalah sama), kita memiliki basis yang lebih kuat jika mengestimasi proporsi populasi tersebut dari kedua sampel secara bersamaan.
Aturan pengambilan keputusan untuk uji proporsi ini sama dengan yang berlaku pada uji rata-rata, yakni: jika statistik uji jatuh di dalam wilayah kritis, kita tolak \(H_0\); sebaliknya, kita gagal menolak \(H_0\).
Setelah memperoleh nilai dari hitungan statistik ujinya, tugas selanjutnya adalah membandingkannya terhadap nilai titik kritis (\(Z_{kritis}\)) dari tabel distribusi di tingkat signifikansi (\(\alpha\)) tertentu. Aturan pengambilan keputusannya senantiasa mengikuti kaidah berikut ini:
- Jika nilai statistik uji jatuh di dalam wilayah kritis, maka hasil pengujian kita adalah hipotesis kosong dapat ditolak (tolak \(H_0\)). Ini berarti statistik yang telah dihitung ternyata memiliki bukti yang cukup untuk menyimpulkan telah terjadi perbedaan yang signifikan antara keadaan rata-rata kedua populasi tersebut.
- Sebaliknya, jika nilai statistik uji tidak jatuh ke dalam wilayah kritis, maka hasil pengujian kita adalah hipotesis kosong gagal ditolak (gagal tolak \(H_0\)). Ini mengindikasikan bahwa data yang dihasilkan nyatanya belum memiliki cukup kekuatan meyakinkan untuk menolak dugaan ketiadaan perbedaan kondisi dari rata-rata kedua populasinya.
Studi Kasus: Uji Rata-Rata Waktu Tempuh Mahasiswa ITERA dan UNILA
Dinas Perhubungan ingin mengetahui apakah rata-rata waktu tempuh perjalanan menuju kampus bagi mahasiswa ITERA berbeda dengan mahasiswa UNILA. Survei taktis pun dilakukan kepada mahasiswa kedua kampus dan berhasil menghimpun sampel sebanyak 428 mahasiswa ITERA yang menghasilkan rata-rata dan simpangan baku, berturut-turut, 5,01 km dan 2,82 km. Sampel mahasiswa UNILA juga berhasil dikumpulkan, yakni sebanyak 394 orang, menghasilkan rata-rata dan simpangan baku, berturut-turut, 2,78 km dan 2,53 km.
Dari data tersebut, menggunakan tingkat kepercayaan 90%, kita akan mencari tahu apakah:
- nilai rata-rata jarak tempuh ke kampus masing-masing, sebesar 5,01 km dan 2,78 km, benar-benar berbeda satu sama lain?
- Jika ya, bagaimana pernyataan ““mahasiswa UNILA secara keseluruhan lebih dekat jarak tempuh ke kampus mereka sendiri ketimbang mahasiswa ITERA?“
Jawaban:
Kita menjalankan langkah-langkah pengujian hipotesis parameter dua populasi independen untuk memutuskan hal tersebut:
Menyatakan Asumsi Awal
Pengujian ini mensyaratkan bahwa kelompok data observasi mahasiswa ITERA dan UNILA adalah independen satu sama lain. Selain itu, tingkat pengukurannya adalah rasio (variabel yang diujikan: jarak tempuh) dan ukuran sampel keduanya memadai (ukuran besar, 428 dan 394) sehingga distribusi statistiknya mendekati normal.-
Menetapkan Hipotesis Kosong dan Alternatif (\(H_0\) dan \(H_1\)) Dalam kasus ini, kita akan menguji apakah rata-rata waktu tempuh mahasiswa ITERA dan UNILA berbeda satu sama lain. Setelah itu, jika berbeda, kita akan menguji apakah rata-rata waktu tempuh mahasiswa UNILA lebih kecil dari mahasiswa ITERA. Dengan demikian, kita menggunakan hipotesis alternatif bentuk tidak berarah dan berarah secara berurutan.
Karena kita berurusan dengan dua populasi, kita misalkan populasi ITERA = 1 dan UNILA = 2. Dengan demikian, kita dapat menuliskan hipotesis alternatif sebagai berikut:
Bentuk tidak berarah:
- Hipotesis Kosong (\(H_0: \mu_1 = \mu_2\)): Rata-rata waktu tempuh mahasiswa ITERA dan UNILA adalah sama. (Kondisi dasar netral/tidak ada perbedaan).
- Hipotesis Alternatif (\(H_1: \mu_1 \ne \mu_2\)): Rata-rata waktu tempuh mahasiswa ITERA dan UNILA berbeda. (Kondisi terdapat perbedaan).
Bentuk berarah:
- Hipotesis Kosong (\(H_0: \mu_1 = \mu_2\)): Rata-rata waktu tempuh mahasiswa ITERA dan UNILA adalah sama.
- Hipotesis Alternatif (\(H_1: \mu_1 > \mu_2\)): Rata-rata waktu tempuh mahasiswa ITERA lebih besar dari mahasiswa UNILA.
-
Menetapkan Wilayah Kritis dari Signifikansi
Untuk hipotesis alternatif bentuk tidak berarah, wilayah penolakan terbagi sama rata di dua unjung kurva penolakan (uji dua ekor/ two-tailed). Sementara itu, untuk hipotesis alternatif bentuk berarah, wilayah penolakan berada di salah satu ujung kurva penolakan (uji satu ekor/ one-tailed).Karena kita menggunakan bentuk pertidaksamaan “lebih besar”, posisi wilayah kritis kita ada di kanan kurva distribusi statisik kita.
Kita diberi tahu bahwa tingkat kepercayaan yang digunakan adalah 90%, sehingga tingkat signifikansi \(\alpha\) adalah 10% atau 0,10. Dengan demikian, kita dapat menentukan wilayah kritis sebagai berikut:
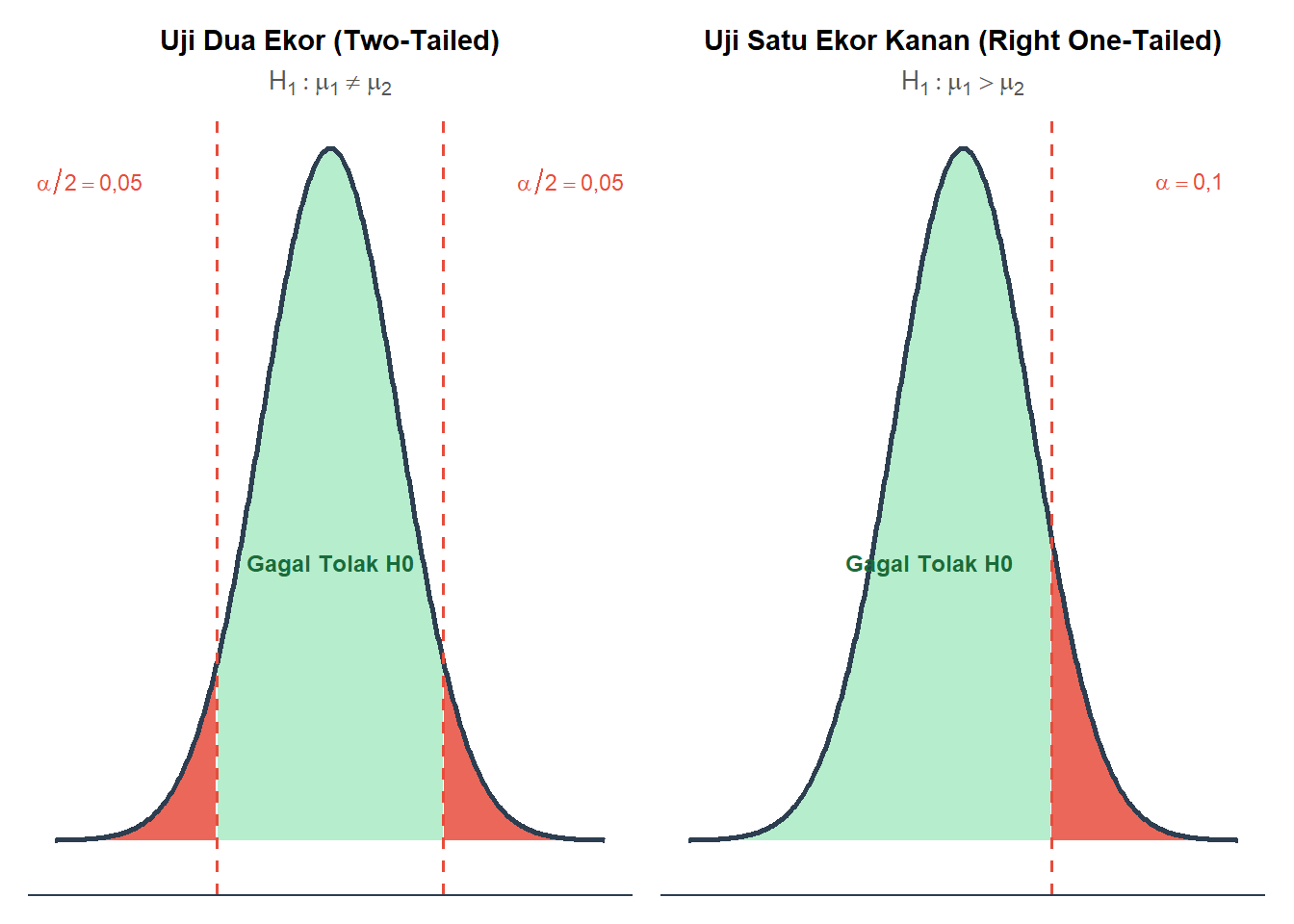
Gambar 8.1: Ilustrasi wilayah kritis: uji dua ekor (kiri) dan uji satu ekor kanan (kanan) pada tingkat signifikansi \(\alpha\) = 10%
-
Mencari Nilai Titik Kritis
Berdasarkan tingkat signifikansi yang ditetapkan (\(\alpha = 10\% = 0,10\)) dan bentuk hipotesis alternatif kita (tidak berarah & berarah), nilai titik kritis kita:- Uji dua ekor: \(Z_{kritis} = \pm 1,64\)
- Uji satu ekor kanan: \(Z_{kritis} = 1,28\)
-
Mencari Nilai Statistik Uji
Perhitungan nilai statistik uji (misalnya \(Z_{hitung}\)) dieksekusi berdasarkan selisih jarak proporsi rata-rata kedua sampel waktu tempuh tersebut setelah dikalibrasi oleh gabungan standard error dari beda rata-rata independen (Persamaan (8.3)).\[\begin{align} Z_{hitung} &= \frac{\bar{X}_1 - \bar{X}_2}{\sqrt{ \dfrac{s_1^2}{N_1 - 1} + \dfrac{s_2^2}{N_2 - 1} }} \nonumber\\ &= \frac{5{,}01 - 2{,}78}{\sqrt{ \dfrac{2{,}82^2}{428 - 1} + \dfrac{2{,}53^2}{394 - 1} }} \nonumber\\ &= \frac{2{,}23}{\sqrt{ \dfrac{7{,}9524}{427} + \dfrac{6{,}4009}{393} }} \nonumber\\ &= \frac{2{,}23}{\sqrt{0{,}01863 + 0{,}01629}} \nonumber\\ &= \frac{2{,}23}{\sqrt{0{,}03492}} \nonumber\\ &= \frac{2{,}23}{0{,}1869} \nonumber\\ &\approx 11{,}93 % \tag{8.6} \end{align}\]
-
Membandingkan Nilai Statistik Uji dan Titik Kritis
Setelah nilainya statistik uji kita peroleh, kita bandingkan posisinya di dalam kurva dengan titik:- Bila \(Z_{hitung}\) melampaui titik kritis sehingga jatuh di dalam wilayah kritis, maka keputusannya kita menolak \(H_0\).
- Sebaliknya, jika tidak, kita gagal menolak \(H_0\).
Berdasarkan hasil perhitungan statistik uji yang telah kita lakukan, nilainya adalah \(+11{,}93\). Karena nilai ini berada jauh di sebelah kanan titik kritis, maka ia jatuh di dalam wilayah kritis. Bahkan, jika kita perhatikan Gambar 8.2, posisi statistik uji kita berada jauh sekali sampai di luar grafik.
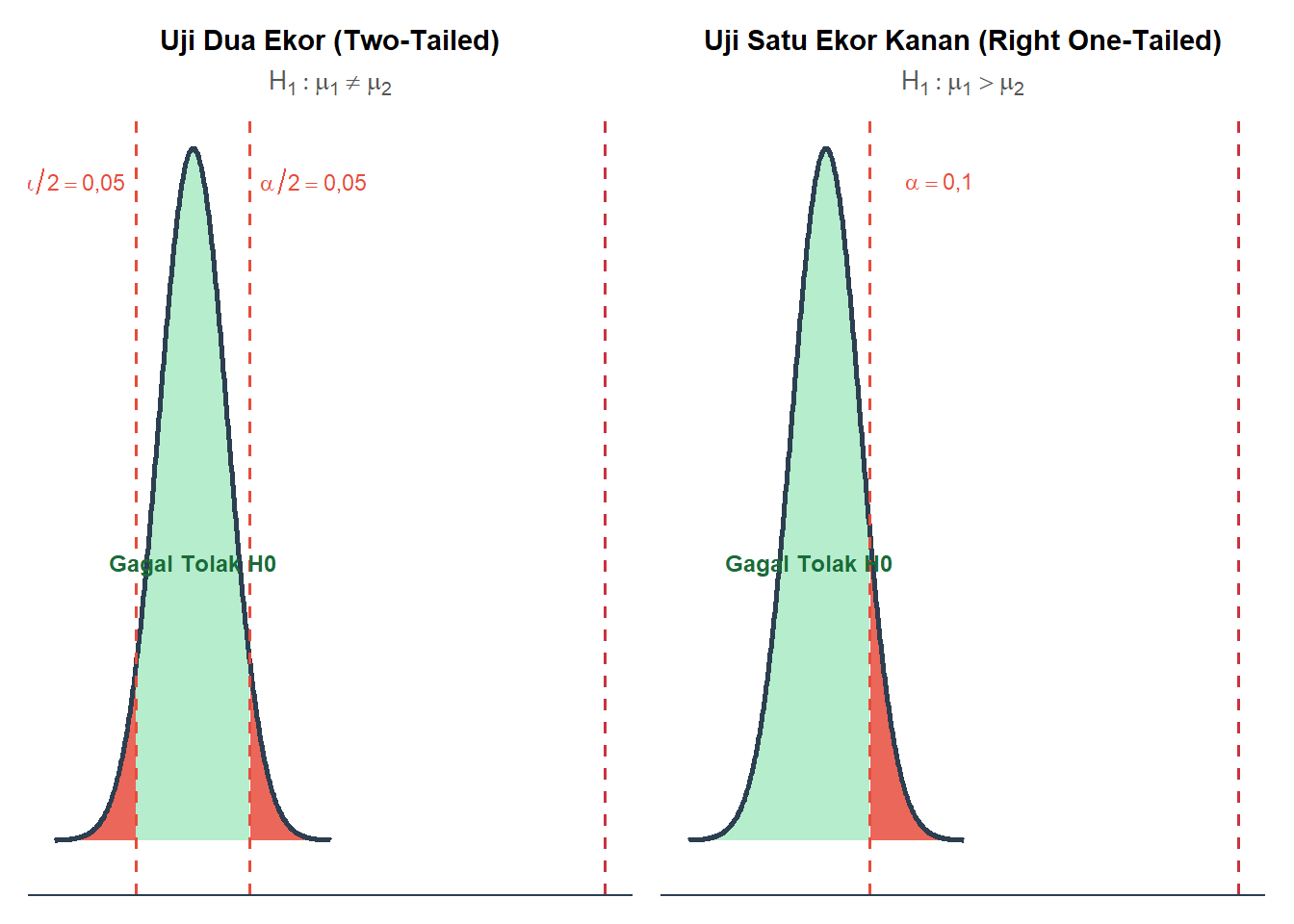
Gambar 8.2: Hasil pengujian hipotesis populasi ITERA dan UNILA
-
Menarik Kesimpulan dan Memaknai Hasil
Hasil perhitungan statistik uji kita jelas menunjukkan bahwa posisinya berada di dalam wilayah kritis, oleh karena kitu, kesimpulan kita adalah kita dapat menolak \(H_0\). Kesimpulannya, sampel observasi cukup untuk membuktikan perbedaan rata-rata waktu tempuh kedua kampus secara kuat (signifikan). Artinya, rata-rata jarak tempuh mahasiswa UNILA ke kampus dibandingkan dengan mahasiswa ITERA memang lebih pendek.
Interpretasi ke dalam bidang PWK: rata-rata jarak tempuh mahasiswa UNILA yang lebih pendek mengindikasikan bahwa kampus UNILA mempunyai struktur ruang yang lebih kompak (kompak) dibandingkan ITERA. Ini dapat dikaitkan dengan pola jaringan jalan yang dimiliki lingkungan di sekitar UNILA yang berbentuk grid sehingga banyak blok-blok guna lahan di sekitarnya yang dapat dimanfaatkan sebagai tempat tinggal.
Lain halnya dengan ITERA, pola jarinagan jalan di sekitar ITERA adalah satu jalan raya memanjang, Jalan Terusan Ryacudu, yang di sekitarnya lebih tersebar (disepersed), mengakibatkan tempat tinggal di sekitarnya juga jadi berjauhan.
Gambar 8.3: Gambaran Struktur Ruang ITERA (dispersed) vs. UNILA (compact)
Simak juga kasus untuk uji hipotesis parameter proporsi untuk dua populasi independen berikut.
Studi Kasus: Uji Proporsi Pengguna Sepeda Motor Mahasiswa ITERA dan UNILA
Dinas Perhubungan ingin mengetahui apakah proporsi mahasiswa yang menggunakan sepeda motor pribadi sebagai kendaraan utama menuju kampus berbeda antara mahasiswa ITERA dan mahasiswa UNILA. Dari data observasi yang ada, tercatat bahwa dari 428 mahasiswa ITERA, sebanyak 260 orang menggunakan sepeda motor, sementara dari 394 mahasiswa UNILA, sebanyak 230 orang juga menggunakan sepeda motor.
Dengan menggunakan tingkat kepercayaan 90%, kita akan menguji apakah proporsi pengguna sepeda motor dari kedua kampus tersebut berbeda secara signifikan.
Jawaban:
Kita jalankan langkah-langkah pengujian hipotesis proporsi dua populasi independen:
Menyatakan Asumsi Awal
Data yang diamati merupakan dua kelompok sampel yang independen — tidak ada hubungan berpasangan antara mahasiswa ITERA dan UNILA. Variabel yang diuji adalah kategorikal dikotomis (menggunakan sepeda motor atau tidak), dan ukuran sampel keduanya cukup besar sehingga memenuhi syarat distribusi normal untuk proporsi.-
Menetapkan Hipotesis Kosong dan Alternatif (\(H_0\) dan \(H_1\))
Kita misalkan populasi ITERA = 1 dan UNILA = 2. Karena kita ingin mengetahui apakah ada perbedaan (tanpa menentukan arah), kita gunakan hipotesis alternatif tidak berarah:- Hipotesis Kosong (\(H_0: P_1 = P_2\)): Proporsi pengguna sepeda motor mahasiswa ITERA dan UNILA adalah sama.
- Hipotesis Alternatif (\(H_1: P_1 \ne P_2\)): Proporsi pengguna sepeda motor mahasiswa ITERA dan UNILA berbeda.
Menetapkan Wilayah Kritis dari Signifikansi
Karena hipotesis alternatif kita tidak berarah, ini merupakan uji dua ekor (two-tailed). Tingkat kepercayaan 90% berarti tingkat signifikansi \(\alpha = 0{,}10\), sehingga masing-masing ujung kurva memuat luas \(\alpha/2 = 0{,}05\).-
Mencari Nilai Titik Kritis
Berdasarkan tabel distribusi normal standar dengan \(\alpha/2 = 0{,}05\):\[Z_{kritis} = \pm 1{,}645\]
-
Mencari Nilai Statistik Uji
Terlebih dahulu kita hitung proporsi masing-masing sampel dan proporsi gabungannya (Persamaan (8.5)):\[\begin{align} \hat{p}_1 &= \frac{260}{428} \approx 0{,}607 \nonumber\\ \hat{p}_2 &= \frac{230}{394} \approx 0{,}584 \nonumber\\ \hat{p} &= \frac{260 + 230}{428 + 394} = \frac{490}{822} \approx 0{,}596 \nonumber \end{align}\]
Kemudian kita hitung nilai statistik ujinya (Persamaan (8.4)):
\[\begin{align} Z_{hitung} &= \frac{\hat{p}_1 - \hat{p}_2}{\sqrt{\hat{p}(1-\hat{p})\left(\dfrac{1}{N_1} + \dfrac{1}{N_2}\right)}} \nonumber\\ &= \frac{0{,}607 - 0{,}584}{\sqrt{0{,}596 \times 0{,}404 \times \left(\dfrac{1}{428} + \dfrac{1}{394}\right)}} \nonumber\\ &= \frac{0{,}023}{\sqrt{0{,}2408 \times 0{,}00487}} \nonumber\\ &= \frac{0{,}023}{\sqrt{0{,}001173}} \nonumber\\ &= \frac{0{,}023}{0{,}0343} \nonumber\\ &\approx 0{,}69 \end{align}\]
Membandingkan Nilai Statistik Uji dan Titik Kritis
Nilai \(Z_{hitung} \approx 0{,}69\) berada di antara \(-1{,}645\) dan \(+1{,}645\), sehingga ia tidak jatuh ke dalam wilayah kritis di kedua ujung kurva.-
Menarik Kesimpulan dan Memaknai Hasil
Karena statistik uji tidak berada di dalam wilayah kritis, keputusan kita adalah gagal menolak \(H_0\). Artinya, data yang tersedia belum cukup untuk membuktikan adanya perbedaan yang signifikan antara proporsi pengguna sepeda motor mahasiswa ITERA dan UNILA pada tingkat kepercayaan 90%.Interpretasi ke dalam bidang PWK: meskipun proporsi pengguna sepeda motor di ITERA (≈60,7%) tampak lebih tinggi dari UNILA (≈58,4%), selisih tersebut tidak cukup signifikan secara statistik. Ini menunjukkan bahwa budaya penggunaan kendaraan bermotor pribadi cenderung serupa di kedua kampus. Dalam konteks perencanaan transportasi, hal ini mengindikasikan bahwa intervensi kebijakan untuk mendorong moda transportasi alternatif — seperti angkutan umum atau sepeda — kemungkinan perlu diformulasikan secara bersamaan untuk kedua kawasan kampus tersebut.
Kerjakan soal evaluasi berikut untuk mengaplikasikan pemahaman kalian mengenai uji hipotesis dua populasi independen.
Soal Evaluasi 15
- Gilang ingin mengetahui apakah selisih rata-rata usia antara seluruh Dosen dengan Tenaga Kependidikan di ITERA sama dengan 1 tahun atau sebenarnya lebih. Dari 73 sampel Dosen, Gilang mendapatkan rata-rata usianya yaitu 30 tahun, sementara dari 69 sampel Tenaga Kependidikan, rata-rata usianya 29 tahun. Simpangan baku sampel Dosen dan Tenaga Kependidikan yang didapatkan Gilang adalah 2,9 tahun dan 2,5 tahun secara berturut-turut. Dengan galat 10%, bantulah Gilang menganalisis hipotesis tersebut. STP-7.1
- Masih dari data yang sama, Gilang juga ingin mengetahui apakah proporsi Dosen yang sudah menikah di ITERA lebih besar dari proporsi Tenaga Kependidikan yang sudah menikah. Dari 73 sampel Dosen, sebanyak 54 orang sudah menikah, sementara dari 69 sampel Tenaga Kependidikan, sebanyak 38 orang sudah menikah. Dengan tingkat kepercayaan 95%, bantulah Gilang menganalisis hipotesis tersebut. STP-7.1
Untuk kedua nomor:
- Nyatakan formulasi hipotesis kosong dan alternatifnya
- Gambarkan distribusi statistiknya untuk menampilkan wilayah dan titik kritis
- Hitung nilai statistik uji. Gambarkan juga dalam distribusi statistik pada poin b.
- Tuliskan keputusan pemilihan hipotesis dan interpretasikan hasilnya.
8.4 Uji Hipotesis Parameter Dua Populasi Berpasangan
Kasus dua populasi berpasangan merujuk pada kondisi di mana terdapat dua populasi yang sama dan saling berkaitan. Kedua populasi ini sebenarnya berasal dari satu populasi yang sama, tetapi diamati dalam dua kondisi yang berbeda, misalnya kondisi sebelum dan sesudah suatu intervensi kebijakan. Atau juga bisa merujuk pada dua populasi yang berbeda namun memiliki karakteristik yang sama sehingga dapat dibandingkan, misalnya membandingkan usia suami dan istri.
Oleh karena populasinya berpasangan, dalam kasus ini kita hanya bisa menghitung rata-rata dari selisih variabel kedua populasi tersebut. Selisih ini biasanya disimbolkan dengan \(D\) (Tjokropandojo et al. 2021).
Karena kita hanya mempunyai 1 angka tunggal, maka pernyataan hipotesis dan juga perhitungan statistik ujinya sama persis teknisnya dengan uji hipotesis satu populasi:
\[\begin{equation} Z_{hitung} = \frac{\bar{D} - \mu_{D_0}}{s_D / \sqrt{n}} \tag{8.7} \end{equation}\]
Di mana:
- \(\bar{D}\) = rata-rata selisih antara dua pengamatan berpasangan
- \(\mu_{D_0}\) = nilai hipotesis rata-rata selisih (bernilai 0 pada \(H_0\))
- \(s_D\) = simpangan baku dari selisih pengamatan
- \(n\) = jumlah pasangan pengamatan
Studi Kasus: Uji Beda Biaya Perjalanan Mahasiswa Sebelum dan Sesudah Pemberlakuan Sistem Angkutan Umum Kampus
Pihak pengelola kampus ingin mengevaluasi efektivitas sistem angkutan umum kampus yang baru diluncurkan dalam menekan biaya transportasi harian mahasiswa. Untuk itu, dilakukan pengambilan data terhadap 35 mahasiswa mengenai biaya perjalanan harian mereka sebelum dan sesudah sistem tersebut beroperasi.
Dari hasil survei, diperoleh rata-rata selisih penurunan biaya perjalanan (\(\bar{D}\)) sebesar Rp5.300,00 dengan simpangan baku selisih (\(s_D\)) sebesar Rp1.800,00. Dengan menggunakan tingkat kepercayaan 95%, apakah kita dapat menyimpulkan bahwa terdapat perbedaan biaya perjalanan yang signifikan akibat adanya sistem angkutan umum tersebut?
Jawaban:
Kita menjalankan langkah-langkah pengujian hipotesis dua populasi berpasangan:
Menyatakan Asumsi Awal
Data yang digunakan adalah berpasangan karena berasal dari subjek yang sama (35 mahasiswa yang sama) pada dua kondisi waktu yang berbeda. Diasumsikan selisih biaya perjalanan berdistribusi normal dengan ukuran sampel \(n = 35\) yang mencukupi untuk pendekatan distribusi normal.-
Menetapkan Hipotesis Kosong dan Alternatif (\(H_0\) dan \(H_1\))
Kita ingin menguji apakah terdapat perbedaan yang signifikan:- Hipotesis Kosong (\(H_0: \mu_D = 0\)): Tidak terdapat perbedaan rata-rata biaya perjalanan mahasiswa antara sebelum dan sesudah adanya angkutan umum.
- Hipotesis Alternatif (\(H_1: \mu_D \ne 0\)): Terdapat perbedaan rata-rata biaya perjalanan mahasiswa antara sebelum dan sesudah adanya angkutan umum.
Menetapkan Wilayah Kritis dari Signifikansi
Tingkat kepercayaan 95% berarti tingkat signifikansi \(\alpha = 0,05\). Karena uji dua ekor, maka wilayah penolakan berada di kedua ujung kurva dengan luas masing-masing \(\alpha/2 = 0,025\).-
Mencari Nilai Titik Kritis
Berdasarkan tabel distribusi normal standar (\(Z\)):\[Z_{kritis} = \pm 1,96\]
-
Mencari Nilai Statistik Uji
Kita menghitung nilai statistik uji \(Z_{hitung}\) untuk data berpasangan:\[\begin{align} Z_{hitung} &= \frac{\bar{D} - \mu_{D_0}}{s_D / \sqrt{n}} \nonumber\\ &= \frac{5.300 - 0}{1.800 / \sqrt{35}} \nonumber\\ &= \frac{5.300}{1.800 / 5{,}916} \nonumber\\ &= \frac{5.300}{304{,}26} \nonumber\\ &\approx 17{,}42 \tag{8.8} \end{align}\]
Membandingkan Nilai Statistik Uji dan Titik Kritis
Nilai \(Z_{hitung} \approx 17{,}42\) jauh lebih besar daripada \(+1,96\), sehingga statistik uji jatuh di dalam wilayah kritis sebelah kanan.Menarik Kesimpulan dan Memaknai Hasil
Karena statistik uji berada di wilayah kritis, maka kita menolak \(H_0\). Ini berarti terdapat bukti statistik yang sangat kuat untuk menyatakan bahwa ada perbedaan biaya perjalanan mahasiswa yang signifikan setelah pemberlakuan sistem angkutan umum kampus.
Interpretasi ke dalam bidang PWK: Penurunan biaya perjalanan yang signifikan menunjukkan bahwa penyediaan infrastruktur transportasi umum yang terintegrasi di kawasan pendidikan efektif dalam meningkatkan efisiensi ekonomi bagi pengguna. Dalam perencanaan wilayah, keberhasilan ini dapat menjadi dasar untuk memperluas jangkauan layanan angkutan umum guna mendorong pergeseran moda (modal shift) dari kendaraan pribadi ke transportasi publik yang lebih berkelanjutan.
Kerjakan soal evaluasi berikut untuk mengaplikasikan pemahaman kalian mengenai uji hipotesis dua populasi berpasangan.
Soal Evaluasi 16
Kampus ITERA melakukan penilaian terhadap Program Bus Kampus, khusus untuk segmen pegawai dan Tenaga Kependidikan (Tendik). Sebanyak 120 orang pegawai dipilih secara acak dan diamati beberapa bulan sebelum dan setelah program berjalan. Hasilnya, rata-rata selisih biaya perjalanan harian (sesudah dikurangi sebelum) yang diperoleh adalah \(-\)Rp250.000 dengan simpangan baku Rp120.000. Dengan galat 10%, buktikanlah apakah selisih tersebut signifikan secara statistik. STP-7.1
- Nyatakan hipotesis nol dan hipotesis alternatif.
- Gambarkan distribusi statistiknya untuk menampilkan wilayah dan titik kritis.
- Hitung nilai statistik uji. Gambarkan juga dalam distribusi statistik pada poin b.
- Tuliskan keputusan pemilihan hipotesis dan interpretasikan hasilnya.
8.5 Uji Hipotesis Parameter Lebih dari Dua Populasi
Selanjutnya, untuk kasus lebih dari dua populasi, konsep dasarnya sama seperti pada kasus dua populasi yang tidak saling berhubungan (independen). Perbedaannya terletak pada jumlah populasi yang dibandingkan, yaitu lebih dari dua dan parameter yang dapat diujikan hanyalah rata-rata.
Selain itu, dalam pengujian ini tidak ada istilah “bentuk hipotesis alternatif”, karena bentuk hipotesis alternatif dalam pengujian ini hanyalah “ada perbedaan”.
8.5.1 Konsep Analysis of Variance (ANOVA)
Pengujian hipotesis parameter lebih dari dua populasi menggunakan teknik yang disebut ANOVA (Analysis of Variance). ANOVA merupakan metode statistik inferensial yang dirancang khusus untuk membandingkan rata-rata dari lebih dari dua populasi atau kelompok.
Teknik ini digunakan untuk menentukan, berdasarkan satu variabel metrik (interval-rasio), apakah sampel-sampel berasal dari populasi yang memiliki rata-rata yang sama.
Secara konsep, ANOVA membandingkan variasi antar kelompok (between-group variance) dengan variasi di dalam kelompok (within-group variance) untuk menilai apakah perbedaan rata-rata yang muncul bersifat signifikan secara statistik atau hanya terjadi karena faktor kebetulan (random error).
8.5.2 Hipotesis Kosong dan Alternatif ANOVA
Bentuk hipotesis kosong dari uji hipoteis parameter lebih dari dua populasi adalah “tidak ada perbedaan rata-rata dalam populasi-populasi yang dibandingkan”.
\[ H_0: \mu_A = \mu_B = \mu_C = ... \]
Sementara itu, bentuk hipotesis alternatifnya hanyalah “salah satu atau lebih dari dua populasi memiliki rata-rata yang berbeda”. Hal ini mengakibatkan tidak ada bentuk pernyataan hipotesis alternatif yang spesifik.
8.5.3 Langkah Pengujian Hipotesis dengan ANOVA
Langkah-langkah pengujian hipotesis menggunakan prosedur ANOVA akan dijelaskan sebagai berikut.
8.5.3.1 Menyatakan Asumsi Awal
Agar prosedur ANOVA dapat dilakukan, terdapat beberapa asumsi yang harus dipenuhi (Healey 2021; de Vaus 2014), di antaranya
- Sampel harus acak dan independen satu sama lain;
- Tingkat pengukuran variabel yang diuji adalah interval-rasio;
- Data terdistribusi normal. Pada dasarnya, ANOVA toleran terhadap beberapa pelanggaran, tetapi keberadaan outlier yang parah akan mengganggu hasil analisis sehingga akan lebih baik jika asumsi ini terpenuhi;
- Variansi kelompok harus kira-kira sama untuk semua populasi.
8.5.3.2 Merumuskan Hipotesis Kosong dan Alternatif
Pada dasarnya, hipotesis dalam prosedur ANOVA memiliki bentuk yang seragam. Peneliti hanya perlu menyesuaikan notasinya sesuai dengan konteks atau kebutuhan penelitian yang dilakukan. Adapun bentuk matematis dari hipotesis dalam analisis ANOVA telah dijelaskan dalam subbab 8.5.2.
Studi Kasus: Uji ANOVA Biaya Perjalanan Tiga Kampus
Dinas Perhubungan melakukan survei biaya perjalanan per bulan (dalam ribu rupiah) dari mahasiswa di tiga kampus yang ada di Bandar Lampung: UIN RIL, UNILA, dan UBL. Ringkasan datanya dihimpun dalam metrik berikut:
| Kampus | Ukuran Sampel | Rata-rata (ribu rupiah) |
|---|---|---|
| UINRIL | 400 | 39,33 |
| UNILA | 394 | 74,00 |
| UBL | 378 | 99,18 |
| Tiga kampus | 1.172 | 70,29 |
Dengan tingkat signifikansi sebesar 5%, apakah perbedaan rata-rata biaya perjalanan di antara ketiga kampus tersebut nyata secara statistik?
Jawaban:
Menyatakan Asumsi Awal
Setiap subjek beserta catatan biayanya dipilah ke dalam sampel pengamatan secara acak dari ketiga kampus tanpa saling mencampuri observasi lainnya (independen). Objek yang diteliti, yaitu biaya, berderajat numerik (interval-rasio). Mengingat besaran cakupan seluruh sampel melintasi rekomendasi kenormalan (>100), sebaran statistik diyakini memadai asumsi berdistribusi normal. Disertai pula asusmi kesetaraan disparitas keberagaman nilainya di rentang proporsi populasi (homogenitas varians).-
Menetapkan Hipotesis Kosong dan Alternatif (\(H_0\) dan \(H_1\))
- Hipotesis Kosong (\(H_0: \mu_{UIN} = \mu_{UNILA} = \mu_{UBL}\)): Tidak terdapat perbedaan signifikan dalam parameter rata-rata rasio biaya perjalanan populasi mahasiswa di ketiga kampus tersebut.
- Hipotesis Alternatif (\(H_1\)): Terdapat setidaknya kelompok dari salah satu kampus yang rata-rata biaya perjalanannya berlainan dibandingkan yang lain.
8.5.3.3 Menentukan Wilayah dan Titik Kritis
Dalam prosedur ANOVA, distribusi sampling yang digunakan adalah distribusi F. Distribusi ini memungkinkan peneliti untuk menguji hipotesis kosong (\(H_0\)) mengenai ada tidaknya perbedaan rata-rata di antara dua kelompok atau lebih.
Bentuk distribusi F bersifat asimetris (miring ke kanan) dan nilainya selalu positif (Gambar 8.4). Hal ini karena nilai F diperoleh dari perbandingan antara dua parameter penting, yaitu variansi antar kelompok (between groups) dan variansi dalam kelompok (within groups).
\[ F = \frac{Variansi\ Antar\ Kelompok}{Variansi\ Dalam\ Kelompok} \tag{8.9} \]
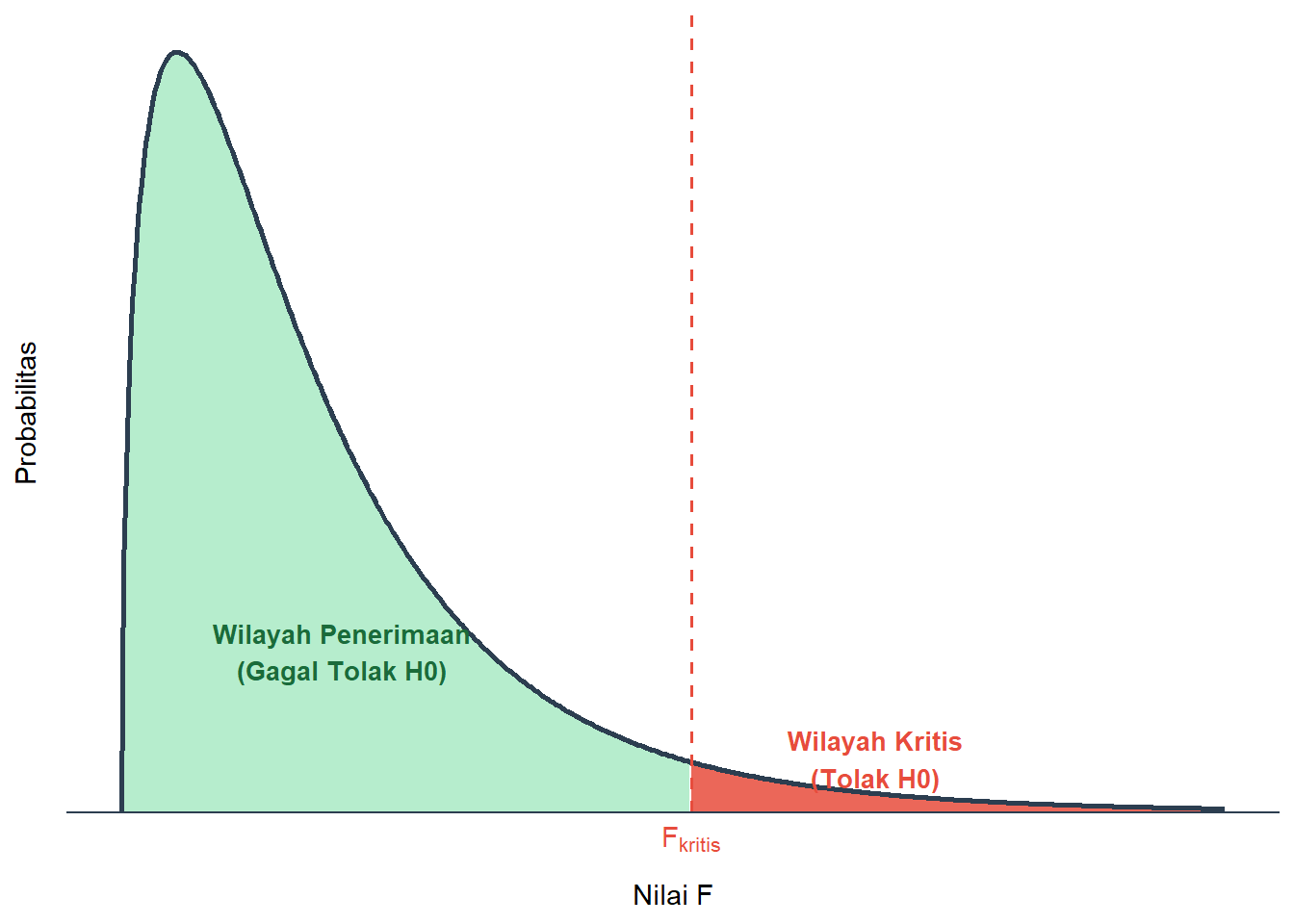
Gambar 8.4: Bentuk Distribusi F dan Wilayah Kritisnya
Makna nilai \(F\) yang besar menunjukkan bahwa perbedaan rata-rata antarkelompok signifikan secara statistik, sedangkan nilai \(F\) yang mendekati 1 menunjukkan bahwa perbedaan antarkelompok cenderung terjadi karena kebetulan.
Menentukan \(F_{kritis}\) dan wilayah kritis pada ANOVA membutuhkan 3 parameter penting: derajat kebebasan di dalam kelompok (degree of freedom within group, \(dfw\)), derajat kebebasan di antara kelompok (degree of freedom between group, \(dfb\)), dan tingkat signifikansi (\(\alpha\)) sebagai wilayah kritis. Ketiga parameter tersebut menjadi penentu nilai \(F_{kritis}\) dari tabel distribusi F.
Nilai \(\alpha\) menjadi variasi tabel, sementara itu di setiap tabel kita menentukan nilai \(F_{kritis}\) berdasarkan nilai \(dfw\) yang bertindak sebagai baris dan \(dfb\) yang bertindak sebagai kolom.
Tabel tersebut dapat kita lihat pada Tabel 14.13 untuk \(\alpha = 5\%\) dan Tabel 14.12 untuk \(\alpha = 10\%\) di bagian Lampiran.
8.5.3.4 Menghitung Statistik Uji
Perhitungan statistik uji, dalam hal ini adalah nilai F dihitung dengan persamaan (8.10) berikut yang merupakan penjabaran dari persamaan (8.9).
\[ F = \frac{MSB}{MSW} \tag{8.10} \]
Di mana \(MSB\) adalah Mean Square Between atau variansi antar kelompok, dan \(MSW\) adalah Mean Square Within atau variansi dalam kelompok.
-
Untuk menghitung \(MSB\) sendiri kita menggunakan persamaan berikut
\[ MSB = \frac{SSB}{dfb} \tag{8.11} \]
\(SSB\) sendiri kita hitung dengan persamaan berikut
\[ SSB = \sum_{i=1}^{k} n_i (\bar{x}_i - \bar{x})^2 \tag{8.12} \]
dengan
- \(n_i\) adalah ukuran sampel dari populasi ke-\(i\)
- \(\bar{x}_i\) adalah rata-rata sampel dari populasi ke-\(i\)
- \(\bar{x}\) adalah rata-rata gabungan sampel dari keseluruhan populasi
-
Untuk menghitung \(MSW\) kita menggunakan persamaan berikut
\[ MSW = \frac{SSW}{dfw} \tag{8.13} \]
Dalam prosedur ANOVA, variasi total dari seluruh skor dibagi menjadi dua komponen utama: variasi di dalam kelompok (\(SSW\)) dan variasi antar kelompok (\(SSB\)). Jika keduanya dijumlahkan, kita mendapatkan nilai variasi total (Total Sum of Squares, \(SST\)) yang dinyatakan sebagai
\[ SST = SSB + SSW \tag{8.14} \]
sehingga \(SSW\) dapat diperoleh dengan
\[ SSW = SST - SSB \tag{8.15} \]
\(SST\) sendiri terlebih dahulu dihitung dengan persamaan
\[ SST = \sum x^2 - N\bar{x}^2 \tag{8.16} \]
dengan
- \(\sum x^2\) adalah jumlah dari kuadrat masing-masing skor observasi
- \(N\) adalah jumlah total observasi dari seluruh kelompok
- \(\bar{x}\) adalah rata-rata gabungan dari seluruh skor (grand mean)
Langkah-langkah menghitung SSW:
Menghitung \(SST\): Kuadratkan setiap skor secara individual, lalu jumlahkan seluruh hasilnya untuk mendapatkan \(\sum x^2\). Selanjutnya, kuadratkan grand mean \(\bar{x}\) dan kalikan dengan jumlah total observasi \(N\). Kurangkan hasil perkalian tersebut dari \(\sum x^2\) untuk mendapatkan nilai \(SST\).
Menghitung \(SSB\): Untuk setiap kelompok ke-\(i\), hitung selisih antara rata-rata kelompok \(\bar{x}_i\) dan grand mean \(\bar{x}\), lalu kuadratkan. Kalikan deviasi yang telah dikuadratkan tersebut dengan jumlah sampel kelompok \(n_i\). Jumlahkan hasil perkalian dari seluruh kelompok untuk mendapatkan nilai \(SSB\) (Persamaan (8.12)).
Menghitung \(SSW\): Kurangkan nilai \(SSB\) dari nilai \(SST\). Selisih inilah yang merupakan nilai \(SSW\) (Persamaan (8.15)).
8.5.3.5 Menarik Kesimpulan
Penarikan kesimpulan dilakukan dengan membandingkan nilai statistik uji, yaitu nilai \(F\) hasil perhitungan (\(F_{uji}\)) terhadap nilai \(F_{kritis}\) dari tabel. \(H_0\) akan ditolak apabila nilai \(F_{uji}\) lebih besar dari nilai \(F_{kritis}\) atau \(F_{uji} > F_{kritis}\), sementara apabila nilai \(F_{uji} < F_{kritis}\), maka hasil pengujian gagal menolak \(H_0\).
Jika kita menggunakan pendekatan p-value yang digunakan di banyak perangkat lunak statistik seperti bahasa R atau SPSS, p-value < signifikansi (\(\alpha\)) berarti kita menolak \(H_0\), sementara jika p-value > signifikansi (\(\alpha\)) maka kita gagal menolak \(H_0\).
Lanjutan Studi Kasus: Uji ANOVA Biaya Perjalanan Tiga Kampus
Setelah menyatakan asumsi dan merumuskan hipotesis, langkah selanjutnya adalah menguji hipotesis tersebut dengan membandingkan \(F_{kritis}\) atau \(F_{tabel}\) dengan \(F_{hitung}\) yang dilakukan sebagai berikut.
-
Menetapkan Wilayah Kritis dan Titik Kritis
Wilayah kritis kita adalah nilai \(\alpha\) yang digunakan untuk pengujian, yakni 5%. Untuk mencari titik kritisnya, maka kita harus menggunakan Tabel \(F\) dengan \(\alpha = 5\%\). Untuk menentukan titik kritisnya, kita menggunakan dua besaran derajat kebebasan \(dfb\) dan \(dfw\).\[ \begin{align} dfb &= K - 1 \\ &= 3 - 1 \\ &= 2 \\ dfw &= N - K \\ &= 1.172 - 3 \\ &= 1.169 \end{align} \]
Oleh karena nilai \(dfw\) sangat besar, kita menggunakan angka tak hingga (\(\infty\)). Dari nilai \(dfb\) yang menjadi kolom dan \(dfw\) yang menjadi baris, kita mendapatkan titik kritis kita sebesar 3,00.
-
Menghitung Statistik Uji Menghitung nilai \(F_{hitung}\) (persamaan (8.10)) memerlukan nilai \(MSB\) dan \(MSW\). Nilai \(MSB\) dan \(MSW\) dihitung dengan persamaan (8.11) dan (8.13) yang dihasilkan dari nilai \(SSB\) dan \(SSW\) (persamaan (8.12) dan (8.15)).
-
Nilai Total Variasi (\(SST\)): Variansi ditelaah pada setiap individu responden untuk dikurangkan terhadap grand mean yang diketahui sebesar 70,29. Mengutip 5 nilai sampel pertama (diketahui berasal dari UNILA: 150, 150, 25, 25, 25), kita menghitung SST sesuai persamaan (8.14):
\(x_i\) \(x_i^2\) 150 22.500 150 22.500 25 625 25 625 25 625 \(\dots\) \(\dots\) \[ \begin{align} \sum x_i^2 &= 22.500 + 22.500 + 625 + 625 + 625 + \dots = 11.205.372 \nonumber\\ SST &= \sum x_i^2 - N\bar{x}^2 \nonumber\\ &= 11.205.372 - 1.172(70,29)^2 \nonumber\\ &\approx \mathbf{5.414.663} \nonumber \end{align} \]
-
Nilai Variasi Antar-Kelompok (\(SSB\)): Variansi ini mengukur seberapa jauh perbedaan rata-rata tiap kampus (\(\bar{x}_j\)) terhadap rata-rata gabungan keseluruhannya (grand mean). Karena jumlah sampel kita sangat banyak, perhitungannya bisa dipersingkat. Kita cukup mencari selisih rata-rata tiap kampus dengan grand mean, mengkuadratkannya, lalu mengalikannya dengan jumlah sampel di kampus tersebut (\(n_j\)):
Kampus (\(j\)) \(n_j\) \(\bar{x}_j\) \((\bar{x}_j - \bar{x})\) \((\bar{x}_j - \bar{x})^2\) \(n_j(\bar{x}_j - \bar{x})^2\) UINRIL 400 39,33 -30,96 958,52 383.408,6 UNILA 394 74,00 3,71 13,76 5.423,1 UBL 378 99,18 28,89 834,63 315.490,9 \[ \begin{align} SSB &= \sum n_j(\bar{x}_j - \bar{x})^2 \\ &= 383.408{,}6 + 5.423{,}1 + 315.490{,}9 \\ &= \mathbf{704.322{,}6} \approx \mathbf{704.352{,}5} \end{align} \]
-
Nilai Variasi Dalam-Kelompok (\(SSW\)): Nilai ini mewakili variasi alami yang memang terjadi di dalam observasi masing-masing kelompok kampus. Alih-alih menghitung rumusnya dari awal satu per satu, kita bisa memanfaatkan sifat penjumlahan komponen variasi secara langsung. Kita cukup mengurangkan variasi total (\(SST\)) dengan variasi antar-kelompok (\(SSB\)):
\[ \begin{align} SSW &= SST - SSB \nonumber\\ &= 5.414.663 - 704.352{,}5 \nonumber\\ &= \mathbf{4.710.310{,}5} \nonumber \end{align} \]
Nilai variasi \(SSB\) dan \(SSW\) yang baru saja kita dapatkan belum bisa dibandingkan secara langsung. Kita harus menstandarkannya terlebih dahulu dengan membaginya menggunakan besaran derajat kebebasannya (\(df\)) masing-masing untuk memperoleh nilai rata-rata kuadrat atau Mean Square (\(MSB\) dan \(MSW\)). Setelah itu, barulah kita bisa mendapatkan nilai \(F_{hitung}\) dari pembagian antara \(MSB\) dan \(MSW\):
\[ \begin{align} MSB &= \frac{SSB}{dfb} \\ &= \frac{704.352{,}5}{2} \\ &= 352.176{,}2 \\ MSW &= \frac{SSW}{dfw} \\ &= \frac{4.710.310{,}5}{1.169} \\ &= 4.029{,}3 \\ F_{hitung} &= \frac{MSB}{MSW} \\ &= \frac{352.176{,}2}{4.029{,}3} \\ &= \mathbf{87{,}4} \end{align} \]
-
Menarik Kesimpulan
Nilai \(F_{hitung}\) yang kita peroleh sebesar 87,4 jauh melampaui rentang nilai penerimaan wajar karena nilainya lebih besar daripada nilai \(F_{kritis}\) sebesar 3,00 (\(F_{hitung} > F_{kritis}\)). Dengan jatuhnya nilai statistik uji ini ke dalam wilayah kritis, keputusan akhir kita adalah menolak hipotesis kosong (\(H_0\)).-
Membahas Interpretasi
Ditolaknya hipotesis kosong menunjukkan bahwa, secara komparatif statistik probabilitas, dapat disimpulkan bahwa terdapat perbedaan rata-rata biaya perjalanan yang nyata (signifikan) minimal untuk salah satu populasi mahasiswa di ketiga kampus tersebut. Asumsi netral (\(H_0\)) bahwa beban pengeluaran transportasi mahasiswa sama berapapun biayanya di setiap kampus kita tolak.Secara realita di lapangan, perbedaan ini bisa menunjukkan adanya karakteristik khas dari kampus tertentu yang membuat mahasiswanya butuh biaya keseharian transportasi mobilitas lebih tinggi (misalnya terkait kepemilikan dan pilihan moda kendaraan pribadi yang lebih mahal, atau keterpencilan lokasi). Bagi instansi pemerintah dan perencana transportasi, pembuktian kesenjangan aksesibilitas ekonomi antarwilayah kampus ini dapat menjadi basis dasar analitik dalam merumuskan penyediaan infrastruktur transportasi massal, program penyediaan bus school, atau kebijakan tarif subsidi publik yang tepat sasaran.
Soal Evaluasi 17
Sebagai bagian dari upaya peningkatan keselamatan di lingkungan kampus, mahasiswa ITERA diwajibkan mematuhi peraturan berkendara, salah satunya adalah menggunakan helm saat mengendarai kendaraan bermotor, termasuk ketika berpindah antar gedung untuk mengikuti perkuliahan.
Rektorat berhipotesis bahwa tingkat kepatuhan mahasiswa terhadap peraturan berkendara, khususnya pemakaian helm, berbeda antar tingkat perkuliahan. Untuk menguji hipotesis tersebut, dilakukan survei selama 30 hari dengan memasang kamera pengawas di beberapa ttiik strategis. Plat nomor motor setiap mahasiswa didata dan dicocokkan dengan identitas mahasiswa yang terdaftar. Algoritma pengenalan plat nomor kendaraan dan pemakaian helm dari rekaman video pun dikembangkan untuk memudahkan pendataan pelanggar. Setiap pelanggar per hari dicatat dan rata-rata jumlah pelanggar dihitung untuk setiap tingkat perkuliahan. Hasil surveinya adalah sebagai berikut
| Tingkat Perkuliahan | Jumlah Sampel | Rata-rata Jumlah Pelanggar |
|---|---|---|
| Tahun Pertama | 200 | 30 |
| Tahun Kedua | 220 | 32 |
| Tahun Ketiga | 310 | 59 |
| Tahun Keempat | 175 | 33 |
Dari data tersebut diperoleh SST sebesar 36.193.660 dan SSB sebesar 153.660. Dengan tingkat signifikansi 0,05 tentukan apakah hipotesis rektorat tersebut berlaku? STP-7.1