Bab 5 Pengantar Analisis Statistik Inferensial
Capaian Pembelajaran
Setelah mempelajari bab ini, Anda diharapkan:
- mampu memilih jenis-jenis pengambilan sampel dalam statistik untuk sebuah kasus. STP-4.1
- mampu menjelaskan hasil perhitungan probabilitas dari suatu nilai sampel dalam distribusi statistik sampel menggunakan standard error. STP-4.2
5.1 Konsep Dasar Statistika Inferensial
Statistika inferensial adalah cabang statistika yang mempelajari penarikan kesimpulan tentang populasi berdasarkan data dari sampel. Konsep-konsep dasar yang perlu dipahami dalam analisis statistika ini meliputi perbedaan antara populasi dan sampel, teknik pengambilan sampel, distribusi sampel dan distribusi statistik sampel, serta prinsip-prinsip terkait distribusi statistik, yakni beberapa di antaranya adalah teorema limit sentral dan distribusi normal.
Setelah memahami konsep-konsep tersebut, kita dapat melanjutkan pembahasan ke penarikan kesimpulan karakteristik populasi dari hasil sampel, yang mencakup pembuatan estimasi parameter dan pengujian hipotesis yang menyatakan karakteristik seluruh populasi dari hasil sampel.
5.2 Populasi vs. Sampel
Populasi adalah seluruh kelompok objek (baik orang, benda, maupun kejadian) yang menjadi target penelitian kita. Ukuran statistik deskriptif dari populasi, seperti rata-rata (\(\mu\)) atau simpangan baku (\(\sigma\)), disebut parameter. Parameter inilah yang sebenarnya ingin diketahui oleh peneliti. Namun, karena jumlah populasi biasanya sangat besar, sering kali kita tidak mungkin mengukur seluruh anggota populasi secara langsung.
Sebaliknya, sampel adalah sebagian kecil dari populasi yang kita ambil untuk diamati. Sampel yang baik harus bisa mewakili sifat keseluruhan populasinya (representatif). Ukuran statistik deskriptif dari sampel inilah yang disebut statistik (seperti rata-rata \(\bar{x}\) atau simpangan baku \(s\)). Nilai statistik ini digunakan untuk menduga nilai parameter populasi.
Mengapa kita mengambil sampel? Alasan utamanya adalah efisiensi dan kelayakan. Menurut Saunders et al. (2023), melakukan sensus terhadap populasi yang besar sering kali tidak praktis karena membutuhkan biaya yang sangat mahal dan waktu yang lama. Selain itu, de Vaus (2014) menekankan bahwa sensus tidak menjamin data yang lebih akurat. Sebaliknya, sampel yang dipilih dengan hati-hati memungkinkan peneliti untuk mengontrol kualitas data dengan lebih ketat (misalnya melalui pelatihan pewawancara yang lebih intensif), sehingga justru dapat menghasilkan tingkat akurasi yang lebih tinggi dibandingkan sensus yang rentan terhadap non-sampling error.
Studi Kasus: Populasi vs. Sampel
Kita ingin menganalisis data karakteristik perjalanan mahasiswa di ITERA. Oleh karena itu, kita mengumpulkan data terstruktur yang mengukur variabel-variabel terkait pola perjalanan mahasiswa di ITERA.
Berdasarkan data tahun 2023 pertengahan, tercatat sebanyak 18.877 mahasiswa aktif di ITERA. Jika kita mengumpulkan seluruh mahasiswa aktif dengan jumlah tersebut, maka kita akan mendapatkan data populasi. Namun, karena jumlah mahasiswa yang sangat banyak, kita tidak mungkin mengumpulkan data seluruh mahasiswa aktif di ITERA. Oleh karena itu, kita mengumpulkan data sebagian mahasiswa aktif di ITERA, yaitu sebanyak 428 mahasiswa.
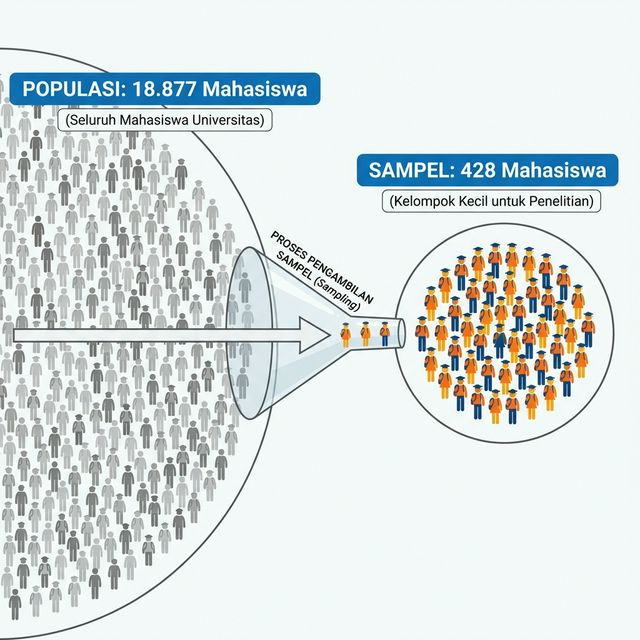
Gambar 5.1: Ilustrasi Perbandingan Populasi Mahasiswa ITERA dan Sampel
Keputusan mengambil 428 sampel ini didasarkan pada pertimbangan efisiensi dan akurasi yang telah kita bahas sebelumnya. Melakukan sensus terhadap 18.877 mahasiswa tentu membutuhkan biaya dan waktu yang sangat besar. Selain itu, dengan jumlah yang jauh lebih sedikit, peneliti dapat lebih fokus menjamin kualitas data (misalnya meminimalisir kesalahan input atau bias wawancara), sehingga data sampel ini diharapkan memiliki kualitas yang lebih baik daripada sensus yang dilakukan secara terburu-buru.
5.3 Teknik-Teknik Pengambilan Sampel (Sampling Techniques)
Teknik pengambilan sampel bertujuan memastikan bahwa sampel yang dipilih benar-benar dapat mewakili populasinya. Healey (2021) menekankan prinsip EPSEM (Equal Probability of Selection Method), yakni prinsip yang menekankan bahwa setiap anggota populasi memiliki kesempatan yang sama untuk dipilih. Hal ini penting untuk menghasilkan sampel yang representatif.
Terdapat dua jenis teknik dalam pengambilan sampel, yakni teknik probabilitas dan teknik non-probabilitas.
5.3.1 Teknik Probabilitas
Teknik probabilitas adalah teknik yang menggunakan prinsip EPSEM. Untuk dapat menggunakannya, kita harus memiliki kerangka sampel. Kerangka sampel adalah daftar seluruh anggota populasi yang akan menjadi acuan kita untuk memilih sampel nantinya. Ada empat jenis teknik yang termasuk ke dalam teknik pengambilan sampel probabilitas Saunders et al. (2023): simple random sampling, systematic sampling, stratified sampling, dan multi-stage cluster sampling.
Studi Kasus: Pengambilan Sampel dengan Populasi Kecil
Untuk mempermudah pemahaman, bayangkan kita memiliki populasi kecil yang terdiri dari 16 orang saja. Setiap orang memiliki atribut Kelompok (A/B/C/D) dan tinggal di Blok tertentu (1/2/3/4).
Berikut adalah data lengkap ke-16 orang tersebut:
| ID | Jarak | Kelompok | Blok | ID | Jarak | Kelompok | Blok |
|---|---|---|---|---|---|---|---|
| 1 | 2,5 | A | Blok 1 | 9 | 10,5 | A | Blok 3 |
| 2 | 1,0 | B | Blok 1 | 10 | 11,2 | B | Blok 3 |
| 3 | 5,2 | C | Blok 1 | 11 | 9,8 | C | Blok 3 |
| 4 | 3,8 | D | Blok 1 | 12 | 8,5 | D | Blok 3 |
| 5 | 0,5 | A | Blok 2 | 13 | 15,0 | A | Blok 4 |
| 6 | 1,2 | B | Blok 2 | 14 | 14,2 | B | Blok 4 |
| 7 | 4,0 | C | Blok 2 | 15 | 16,5 | C | Blok 4 |
| 8 | 6,1 | D | Blok 2 | 16 | 13,8 | D | Blok 4 |
Mari kita terapkan keempat teknik sampling untuk memilih sampel dari 16 orang ini.
5.3.1.1 Simple Random Sampling
Simple random sampling merupakan teknik paling dasar dalam pengambilan sampel probabilistik. Kita mengambil secara acak nomor yang merepresentasikan nomor urut sampel. Ini memungkinkan setiap anggota populasi memiliki peluang yang sama untuk dipilih. Pemilihan anggota sampel secara acak ini dapat dilakukan dengan bantuan sistem eksternal dari peneliti, misalnya melalui tabel angka acak atau program komputer yang menghasilkan angka acak (random number generator) (Gambar 5.2).
Gambar 5.2: Ilustrasi Simple Random Sampling
Catatan: Miskonsepsi tentang Istilah Random
Banyak yang salah kaprah dengan istilah random pada simple random sampling. Keacakan (random) di sini maksudnya bukan asal mengambil sampel secara acak langsung di dunia nyata, akan tetapi kita mengambil sampel tersebut dari sebuah kerangka sampel, elemen vital dalam teknik sampling probabilitas.
Studi Kasus: Simple Random Sampling dengan Populasi Kecil
Misalkan kita menggunakan random number generator yang ada di hampir semua program spreadsheet untuk memilih 4 sampel. Hasilnya adalah 4 orang yang terpilih secara acak tanpa pola tertentu.
| ID | Jarak | Kelompok | Blok |
|---|---|---|---|
| 9 | 10,5 | A | Blok 3 |
| 16 | 13,8 | D | Blok 4 |
| 14 | 14,2 | B | Blok 4 |
| 7 | 4,0 | C | Blok 2 |
5.3.1.2 Systematic Random Sampling
Berbeda dengan simple random sampling, systematic random sampling menggunakan sistem pemilihan berdasarkan interval tertentu. Langkah pertama adalah menentukan angka acak awal, kemudian memilih sampel berikutnya berdasarkan kelipatan dari angka tersebut.
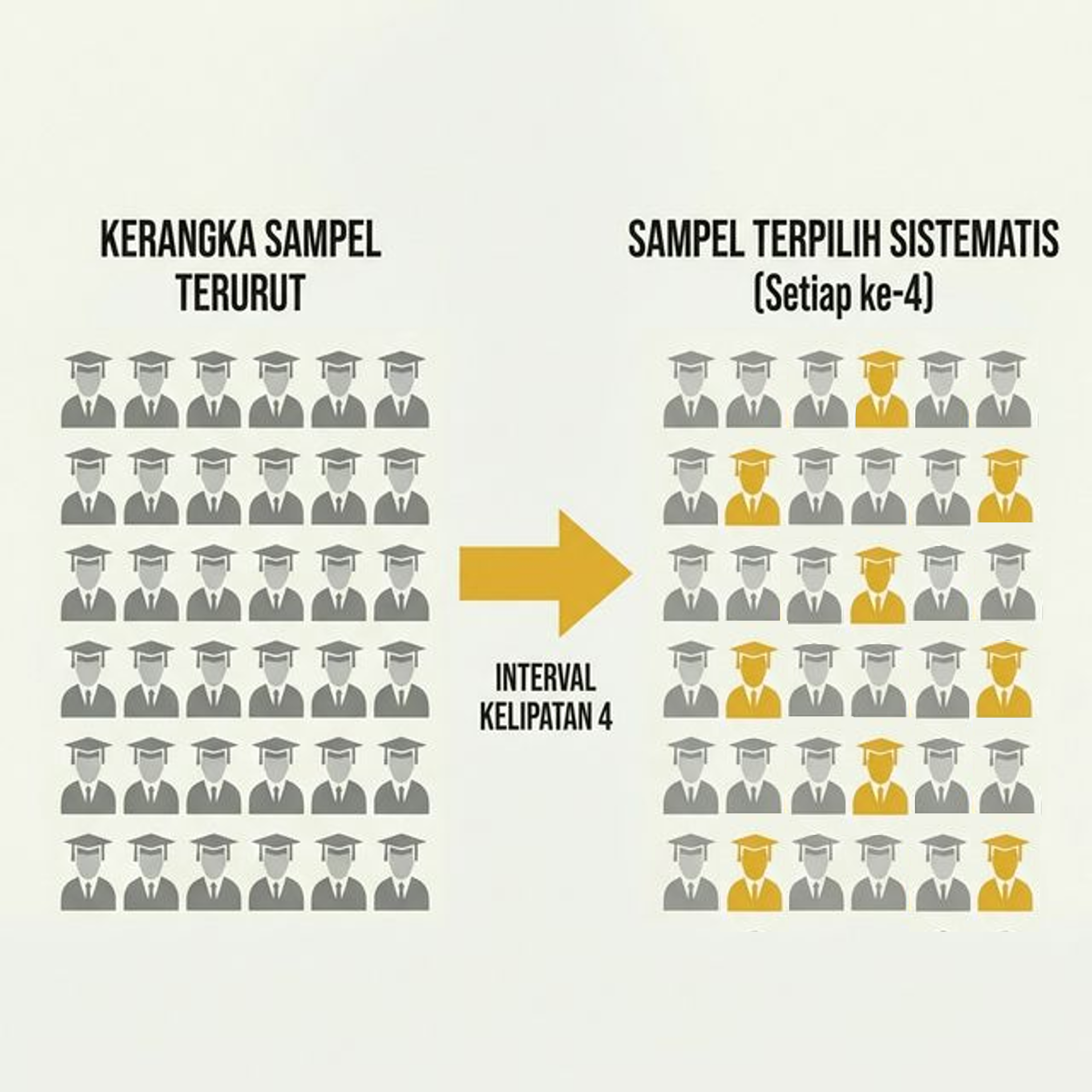
Gambar 5.3: Ilustrasi Systematic Random Sampling
Studi Kasus: Systematic Sampling dengan Populasi Kecil
Kita ingin mengambil sampel dengan interval k=4. Kita urutkan berdasarkan ID, lalu ambil setiap kelipatan 4 (4, 8, 12, 16).
| ID | Jarak | Kelompok | Blok |
|---|---|---|---|
| 4 | 3,8 | D | Blok 1 |
| 8 | 6,1 | D | Blok 2 |
| 12 | 8,5 | D | Blok 3 |
| 16 | 13,8 | D | Blok 4 |
Perhatikan pola ID yang terpilih selalu berjarak 4 angka.
5.3.1.3 Stratified Random Sampling
Dalam beberapa kasus, populasi terdiri atas kelompok-kelompok, disebut strata, yang memiliki karakteristik yang sama didalamnya, misalnya jumlah anggota rumah tangga, tingkat pendidikan, atau status sosial ekonomi. Agar setiap kelompok terwakili, digunakanlah teknik stratified random sampling. Caranya adalah dengan membagi populasi ke dalam beberapa strata sesuai karakteristik yang relevan, kemudian mengambil sampel secara proporsional dari setiap strata.
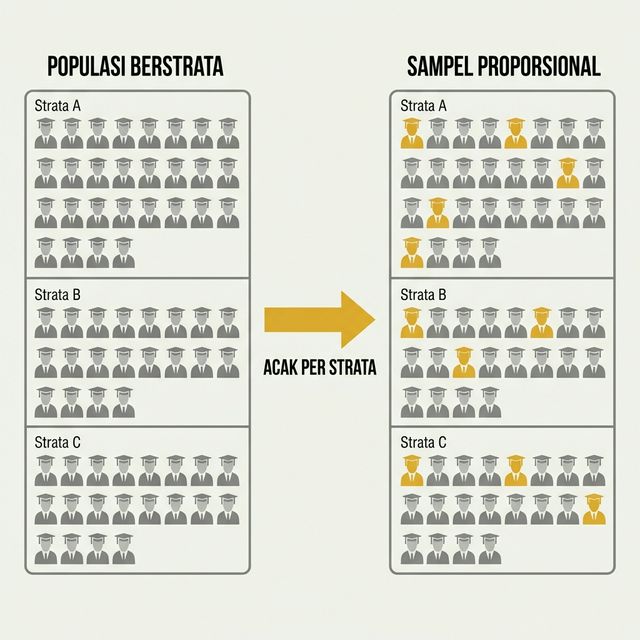
Gambar 5.4: Ilustrasi Stratified Random Sampling
Studi Kasus: Stratified Random Sampling dengan Populasi Kecil
Kita ingin memastikan setiap Kelompok (A, B, C, D) terwakili. Kita bagi populasi menjadi 4 strata (Kelompok), lalu ambil 1 orang acak dari setiap strata.
| ID | Jarak | Kelompok | Blok |
|---|---|---|---|
| 9 | 10,5 | A | Blok 3 |
| 6 | 1,2 | B | Blok 2 |
| 3 | 5,2 | C | Blok 1 |
| 16 | 13,8 | D | Blok 4 |
Hasilnya menjamin ada masing-masing satu perwakilan dari Kelompok A, B, C, dan D.
5.3.1.4 Multi-Stage Cluster Sampling
Teknik ini digunakan ketika kerangka sampel individu tidak tersedia, tetapi kerangka sampel untuk kelompok (klaster) tersedia. Misalnya, kita tidak punya daftar nama seluruh penduduk kota, tetapi kita punya kerangka sampel nama-nama kelurahan. Kita bisa memilih beberapa kelurahan secara acak (tahap 1), kemudian menghasilkan kerangka sampel baru dari kelurahan yang terpilih tersebut, misalnya berdasarkan batas administratif (RW/lingkungan), atau berdasarkan batas fisik, seperti blok-blok jalan (tahap 2). Dari kerangka sampel tersebut kita pilih lagi secara acak anggota kerangka sampel tersebut.
Gambar 5.5: Ilustrasi Multi-Stage Cluster Sampling
Studi Kasus: Multi-Stage Cluster Sampling dengan Populasi Kecil
Kita ingin menghemat tenaga dengan hanya mendatangi satu lokasi saja. Kita pilih secara acak 1 Blok (Cluster), lalu ambil semua orang di blok tersebut.
| ID | Jarak | Kelompok | Blok |
|---|---|---|---|
| 13 | 15,0 | A | Blok 4 |
| 14 | 14,2 | B | Blok 4 |
| 15 | 16,5 | C | Blok 4 |
| 16 | 13,8 | D | Blok 4 |
Kita hanya perlu mendatangi satu lokasi (Blok), tapi mendapatkan 4 responden sekaligus.
5.3.2 Teknik Non-probabilitas
Jika teknik probabilitas memerlukan kerangka sampel sebagai bahan pengambilan sampel, maka teknik non-probabilitas tidak memerlukan kerangka sampel, alias kita tidak perlu membuat daftar seluruh anggota populasi terlebih dahulu untuk mengambil sampel.
Penggunaan sampel nonprobabilitas biasanya dilakukan ketika peneliti tidak memiliki kerangka sampel (sampling frame) yang memadai, atau ketika penggunaan sampel probabilitas dianggap tidak praktis, terlalu mahal, dan memakan waktu lama. Selain itu, teknik ini sering diaplikasikan pada tahap awal penelitian eksploratori, seperti pengujian awal kuesioner (pilot testing) (de Vaus 2014; Saunders et al. 2023).
Berikut adalah beberapa teknik pengambilan sampel nonprobabilitas yang umum digunakan:
- Convenience atau Haphazard Sampling: Pemilihan kasus didasarkan pada kemudahan akses bagi peneliti, seperti mewawancarai orang yang kebetulan ditemui di pusat perbelanjaan atau menggunakan mahasiswa di kelas sendiri sebagai subjek penelitian.
- Quota Sampling: Teknik ini bertujuan untuk memastikan bahwa sampel yang diambil mewakili karakteristik tertentu dari populasi (seperti usia atau jenis kelamin) dengan menetapkan kuota tertentu bagi setiap kategori. Meskipun terlihat representatif dalam karakteristik yang ditetapkan, pemilihannya tetap tidak dilakukan secara acak.
-
Purposive atau Judgemental Sampling: Peneliti menggunakan pertimbangan profesionalnya untuk memilih kasus yang dianggap paling informatif atau tipikal guna menjawab pertanyaan penelitian. Terdapat beberapa variasi dari teknik ini, antara lain:
- Kasus Ekstrem (Extreme Case): Fokus pada kasus yang sangat tidak biasa untuk mempelajari fenomena secara mendalam.
- Heterogen (Maximum Variation): Memilih kasus yang sangat beragam untuk mengidentifikasi tema-tema utama yang muncul di berbagai kondisi.
- Kasus Kritis (Critical Case): Memilih kasus yang dianggap sangat penting karena jika suatu fenomena terjadi di sana, maka besar kemungkinan akan terjadi di tempat lain.
- Snowball Sampling: Teknik ini dimulai dengan beberapa partisipan awal yang kemudian diminta untuk mengidentifikasi atau merekomendasikan anggota populasi lainnya yang sulit dijangkau. Metode ini sangat berguna untuk meneliti kelompok masyarakat yang “tersembunyi”.
- Volunteer atau Self-selection Sampling: Individu secara sukarela mendaftarkan diri atau merespons undangan peneliti untuk berpartisipasi dalam penelitian.
Keterbatasan utama dari sampel nonprobabilitas adalah ketidakmampuannya untuk digunakan dalam generalisasi statistik ke populasi yang lebih luas. Karena tidak berdasarkan prinsip Equal Probability of Selection Method (EPSEM), peneliti tidak dapat menghitung margin kesalahan atau tingkat kepastian hasil secara matematis. Oleh karena itu, kesimpulan dari penelitian ini biasanya bersifat terbatas pada kelompok yang diuji atau digunakan untuk membangun teori yang perlu diuji lebih lanjut melalui metode probabilitas.
Soal Evaluasi 6
STP-4.3 Sebuah acara keakraban angkatan Anda akan dilakukan di suatu tempat yang memerlukan biaya sewa tempat. Agar acara Anda dihadiri sebanyak mungkin orang, Anda menanyakan kesediaan kawan-kawan Anda. Anda pun merancang sebuah survei untuk mengetahui persentase kawan Anda yang setuju acara keakraban diadakan di tempat tersebut. Untuk itu Anda menanyakan sebagian kawan Anda sebagai sampel.
- Apabila Anda memiliki daftar nama seluruh kawan Anda, apa nama teknik pengambilan sampel yang Anda bisa lakukan?
- Jelaskan bagaimana metode Anda memilih sampel kawan Anda berdasarkan kondisi di soal ke-1 tersebut.
- Apabila Anda tidak memiliki daftar nama seluruh kawan Anda, apa nama teknik pengambilan sampel yang Anda bisa lakukan?
- Jelaskan bagaimana metode Anda memilih sampel kawan Anda berdasarkan kondisi di soal ke-3 tersebut.
5.4 Menentukan Ukuran Sampel
Jika selama ini kita masih berpikir bahwa ukuran sampel (jumlah sampel yang menjadi bahan data kita) ditentukan berdasarkan ukuran populasinya, maka kita salah kaprah. Menurut de Vaus (2014), ukuran sampel menentukan galat dari perkiraan kita terhadap populasi, tapi ukuran sampel bukan ditentukan dari ukuran populasi. de Vaus (2014) juga menjabarkan jumlah-jumlah sampel yang berbeda untuk setiap galat dari perkiraan kita. Galat perkiraan ini disebut juga dengan sampling error. Tabel 5.6 menunjukkan ukuran sampel minimum berdasarkan sampling error pada varians 50/50, tingkat kepercayaan 95%. Ini akan kita pelajari lebih dalam di Bab 6.
| Sampling error | Ukuran Sampel Min. | Sampling error | Ukuran Sampel Min. |
|---|---|---|---|
| 1,0% | 10.000 | 5,5% | 330 |
| 1,5% | 4.500 | 6,0% | 277 |
| 2,0% | 2.500 | 6,5% | 237 |
| 2,5% | 1.600 | 7,0% | 204 |
| 3,0% | 1.100 | 7,5% | 178 |
| 3,5% | 816 | 8,0% | 156 |
| 4,0% | 625 | 8,5% | 138 |
| 4,5% | 494 | 9,0% | 123 |
| 5,0% | 400 | 9,5% | 110 |
| 10,0% | 100 |
Studi Kasus: Menentukan Jumlah Sampel dari Tabel
Seorang mahasiswa ingin meneliti proporsi mahasiswa ITERA yang menggunakan kendaraan bermotor sebagai moda utama perjalanan ke kampus. Ia merancang survei dan perlu menentukan berapa responden yang harus ia kumpulkan.
Karena ia belum tahu berapa proporsi sesungguhnya di populasi, ia menggunakan asumsi terburuk: 50% menggunakan kendaraan bermotor dan 50% tidak (varians 50/50). Ia juga menetapkan bahwa sampling error yang masih dapat ia tolerir adalah 5% pada tingkat kepercayaan 95%.
Dengan membaca Tabel 5.6 pada baris sampling error 5,0%, ia menemukan bahwa sampel minimum yang dibutuhkan adalah 400 responden. Jumlah inilah yang ia jadikan target pengumpulan data.
Perhatikan bahwa angka ini tidak bergantung pada seberapa besar populasi mahasiswa ITERA (yang berjumlah lebih dari 18.000 orang). Cukup 400 responden, dan hasil surveinya akan memiliki akurasi dalam batas ±5% pada tingkat kepercayaan 95%.
5.5 Konsep Distribusi dalam Statistik
Dalam stastistika inferensial, kita harus menguasai konsep mengenai distribusi. Distribusi adalah penyebaran suatu nilai yang memiliki karakteristik tertentu. Di sini, tujuan kita adalah mengenali apa yang kami akan sebut dengan distribusi objek dan distribusi statistik, atau yang dalam Healey (2021) dan Ewing and Park (2020) disebut distribusi sampel dan distribusi hasil sampel (sampling distribution).
5.5.1 Model-model Distribusi Statistik
Terdapat banyak jenis model distribusi dalam statistik yang sering dipakai. Beberapa jenis model statisik yang populer misalnya adalah distribusi uniform (seragam), distribusi binomial, distribusi Poisson, dan distribusi normal atau Gaussian (Thulin 2021). Namun, dalam pembahasan statistika inferensial di buku ini kita hanya akan fokus pada distribusi normal dan turunannya, distribusi Student’s t, beserta distribusi binomial, distribusi F, dan distribusi Chi-square.
Seperti yang ditampilkan oleh Gambar 5.6 berikut, setiap jenis distribusi statistik mempunyai berbagai bentuknya. Bentuk-bentuk ini pada hakikatnya adalah histogram-histogram representasi sebaran nilai-nilai sekumpulan objek.
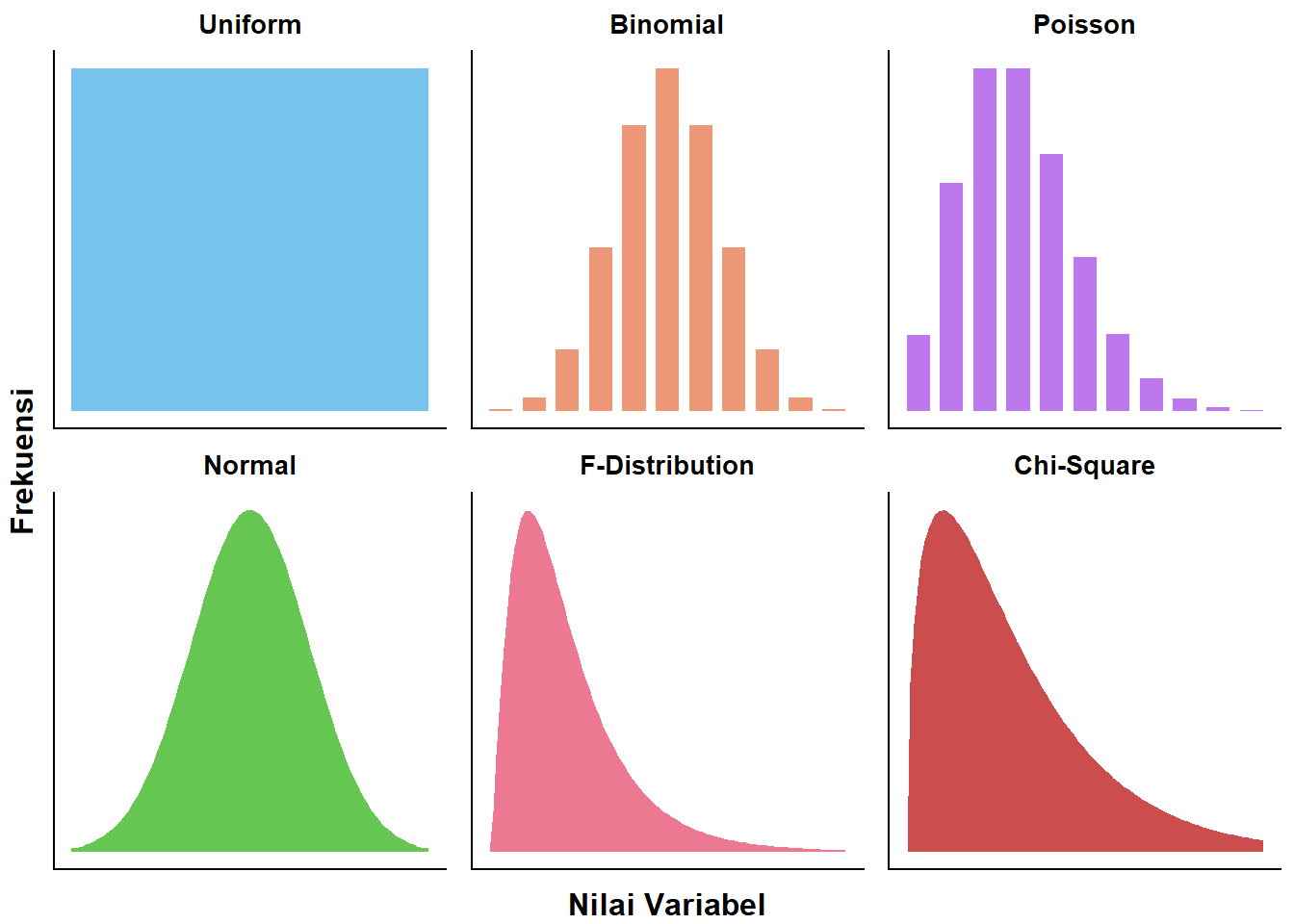
Gambar 5.6: Ragam Bentuk Distribusi Statistik
Interpretasi Bentuk Distribusi
Seperti yang sudah dijelaskan bahwa bentuk distribusi sebenarnya adalah histogram, kita sudah belajar bahwa histogram memiliki 2 sumbu: sumbu X dan Y/mendatar dan tegak, yang masing-masing artinya adalah rentang nilai dan frekuensi kemunculan nilai tersebut secara berturut-turut.
Begitu juga gambar-gambar distribusi tersebut. Sumbu X mencerminkan nilai-nilai yang terdapat dalam objek-objek yang dinyatakan distribusinya, sumbu Y jumlah kemunculan nilai-nilai tersebut. Selain dipahami sebagai jumlah, sumbu Y juga bisa diinterpretasikan sebagai probabilitas kemunculan nilai-nilai tersebut.
5.5.2 Distribusi Normal
Distribusi normal adalah salah satu jenis distribusi nilai yang memiliki karakteristik berbentuk seperti lonceng, simetris, dan membentang tanpa batas di kedua sisi sumbu horizontal (Tjokropandojo et al. 2021). Oleh karena itu, model distribusi ini juga disebut bell curve atau kurva lonceng (Healey 2021) (Gambar 5.7).
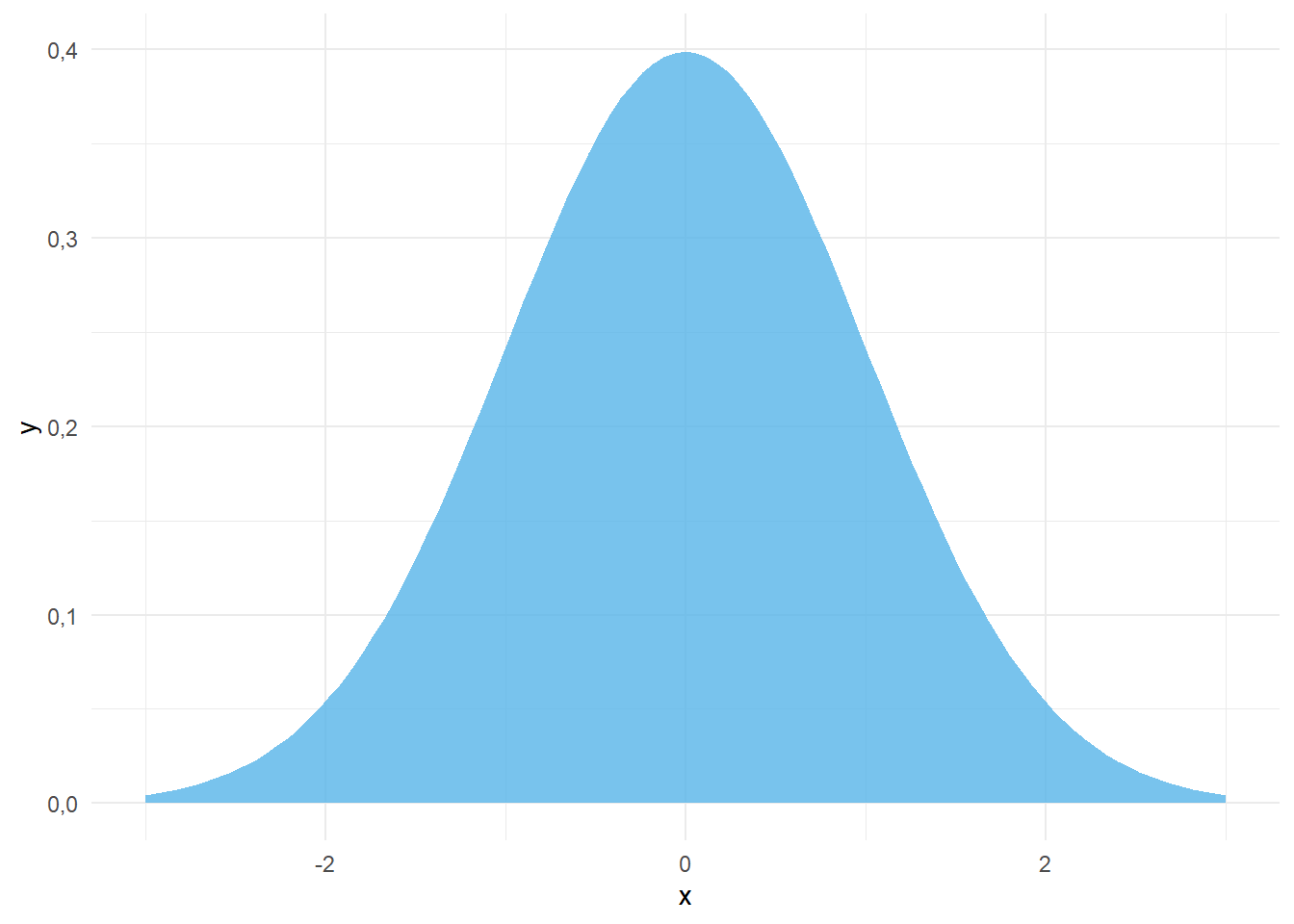
Gambar 5.7: Distribusi Normal
Dari Gambar 5.7, kita dapat melihat bahwa distribusi normal memiliki beberapa karakteristik utama berikut:
- Parameter Utama: Distribusi normal ditentukan sepenuhnya oleh dua parameter: rata-rata (mean atau \(\mu\)) dan varians (\(\sigma^2\)) (Chan 2021a). Rata-rata menentukan lokasi tengah distribusi, sedangkan varians (atau standar deviasi) menentukan lebar atau penyebaran kurva (Healey 2021; Hair et al. 2013).
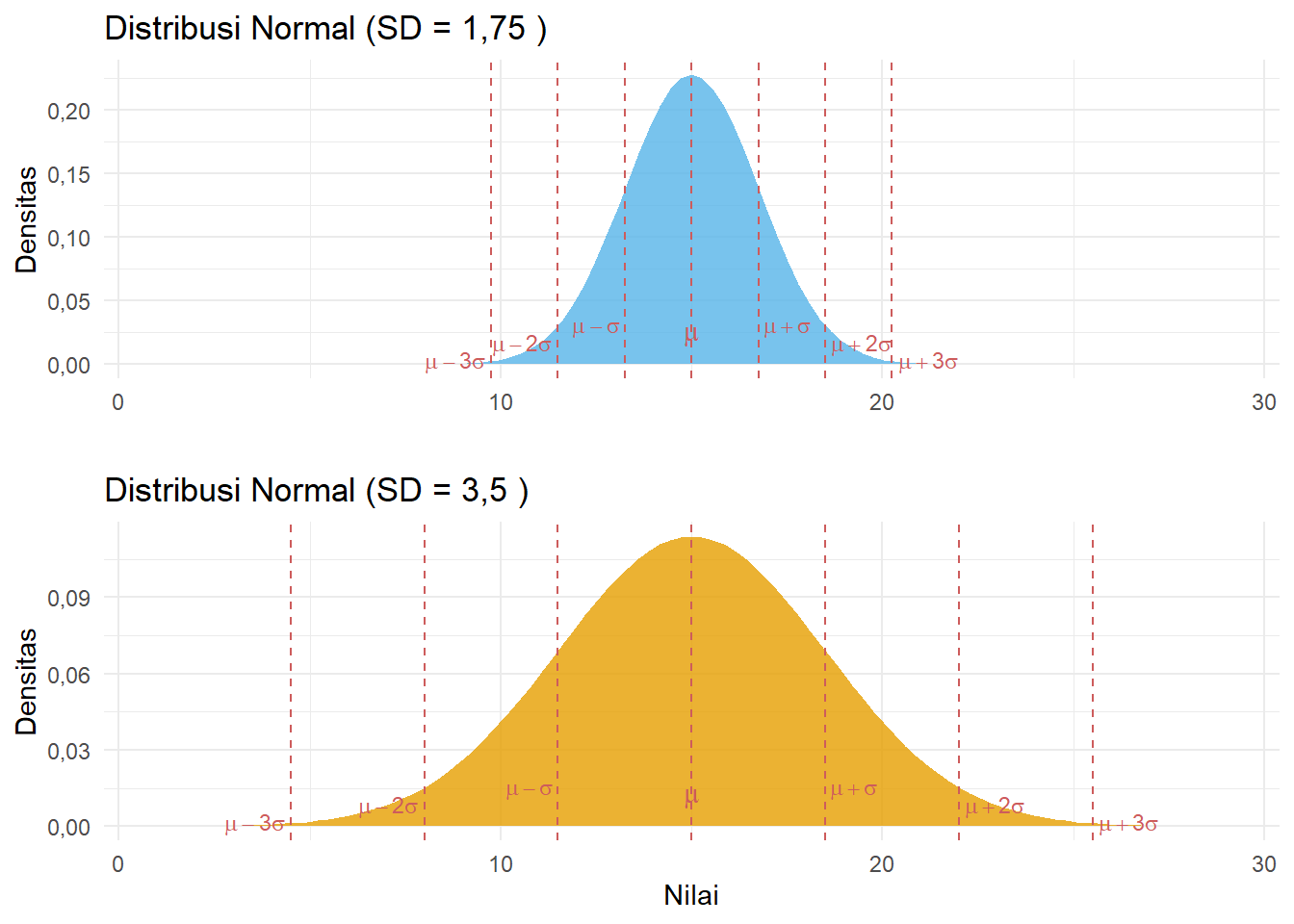
Gambar 5.8: Perbandingan Distribusi Normal dengan Rata-rata Sama namun Standar Deviasi Berbeda
Simetri Sempurna: Pada distribusi normal yang sempurna, nilai mean (rata-rata), median (nilai tengah), dan mode (nilai yang paling sering muncul) adalah identik dan berada tepat di tengah distribusi (Healey 2021; de Vaus 2014).
-
Skewness dan Kurtosis:
Skewness (Kemencengan): Distribusi normal memiliki nilai skewness 0, yang menunjukkan simetri sempurna. Jika data menumpuk di kiri, itu disebut positive skew, dan jika di kanan disebut negative skew (de Vaus 2014; Ewing and Park 2020).
Kurtosis (Keruncingan): Mengukur keruncingan atau kedataran puncak distribusi relatif terhadap distribusi normal. Distribusi normal memiliki nilai kurtosis 3. Distribusi yang lebih runcing disebut leptokurtik (>3), dan yang lebih datar disebut platikurtik (<3) (Chan 2021a; Ewing and Park 2020).
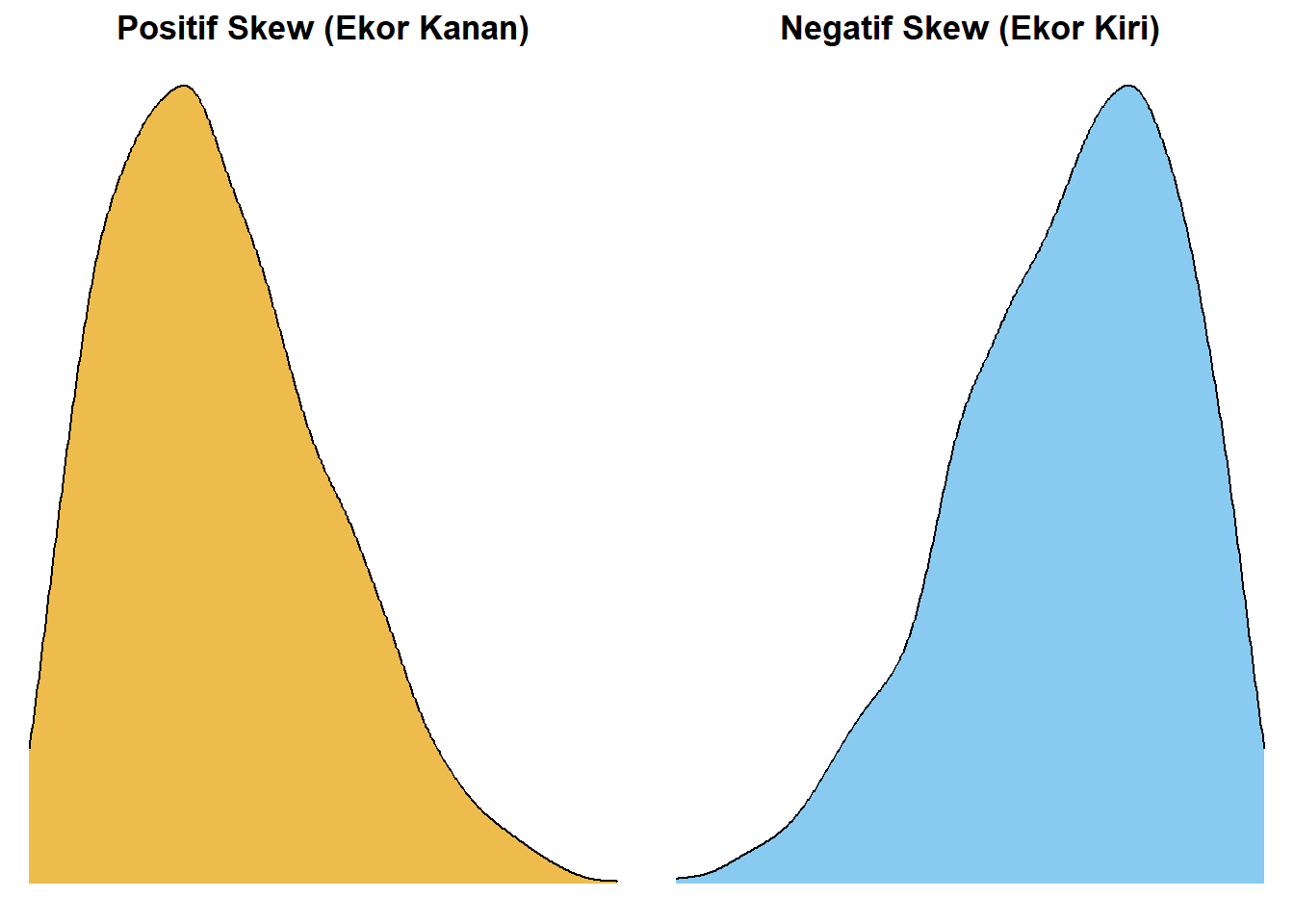
Gambar 5.9: Ilustrasi Positive dan Negative Skewness
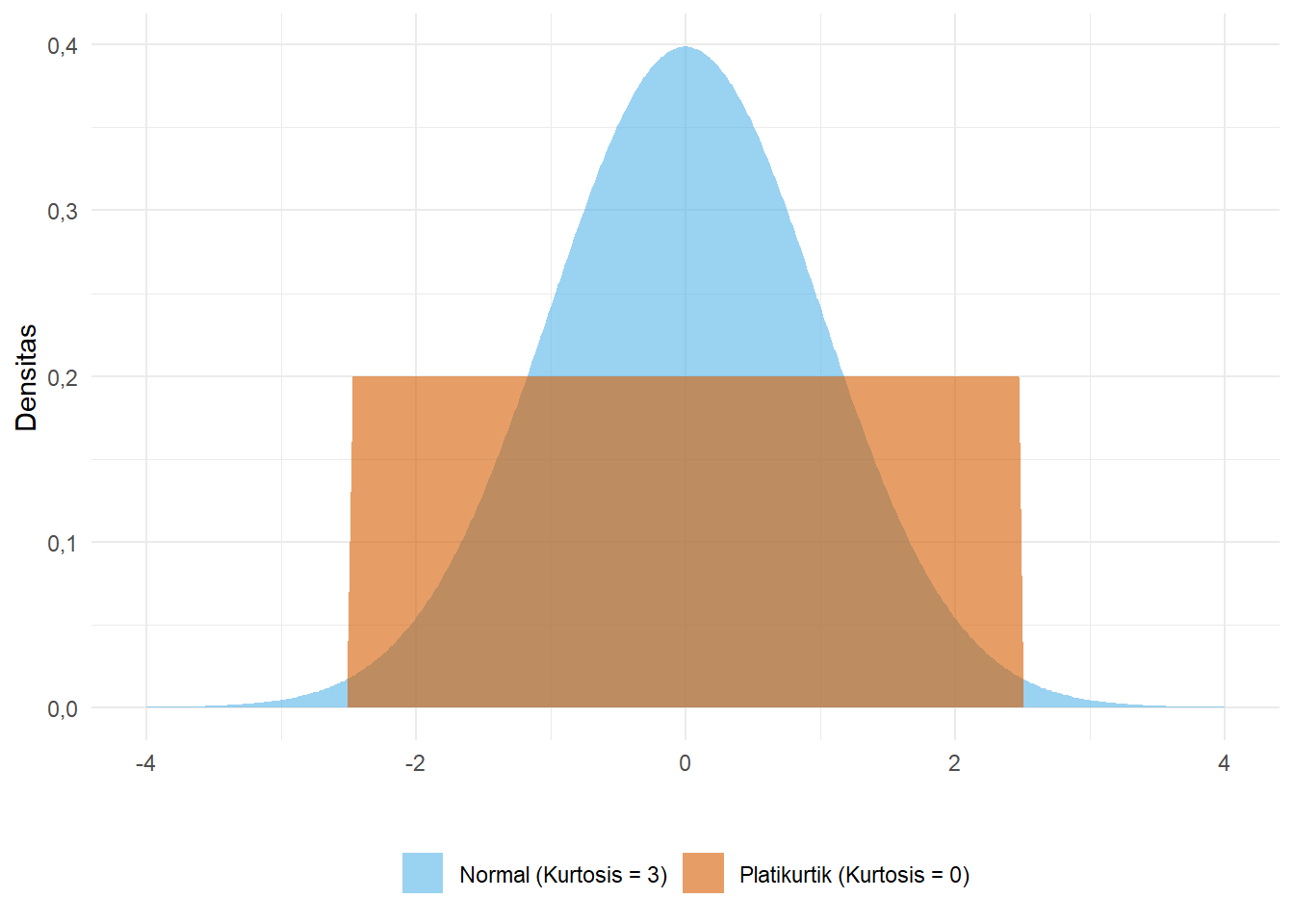
Gambar 5.10: Perbandingan Kurtosis: Normal (3) vs Platikurtik (<3)
-
Area di Bawah Kurva (Aturan 68-95-99, Aturan Empiris): Salah satu karakteristik paling berguna adalah proporsi area di bawah kurva yang tetap berdasarkan jarak standar deviasi (SD) dari rata-rata (Healey 2021):
- \(\pm\) 1 SD mencakup sekitar 68,26% dari total kasus.
- \(\pm\) 2 SD mencakup sekitar 95,44% dari total kasus.
- \(\pm\) 3 SD mencakup sekitar 99,72% dari total kasus.
Ini mengimplikasikan bahwa kejadian yang berada jauh di luar 3 standar deviasi dari rata-rata sangat jarang terjadi.
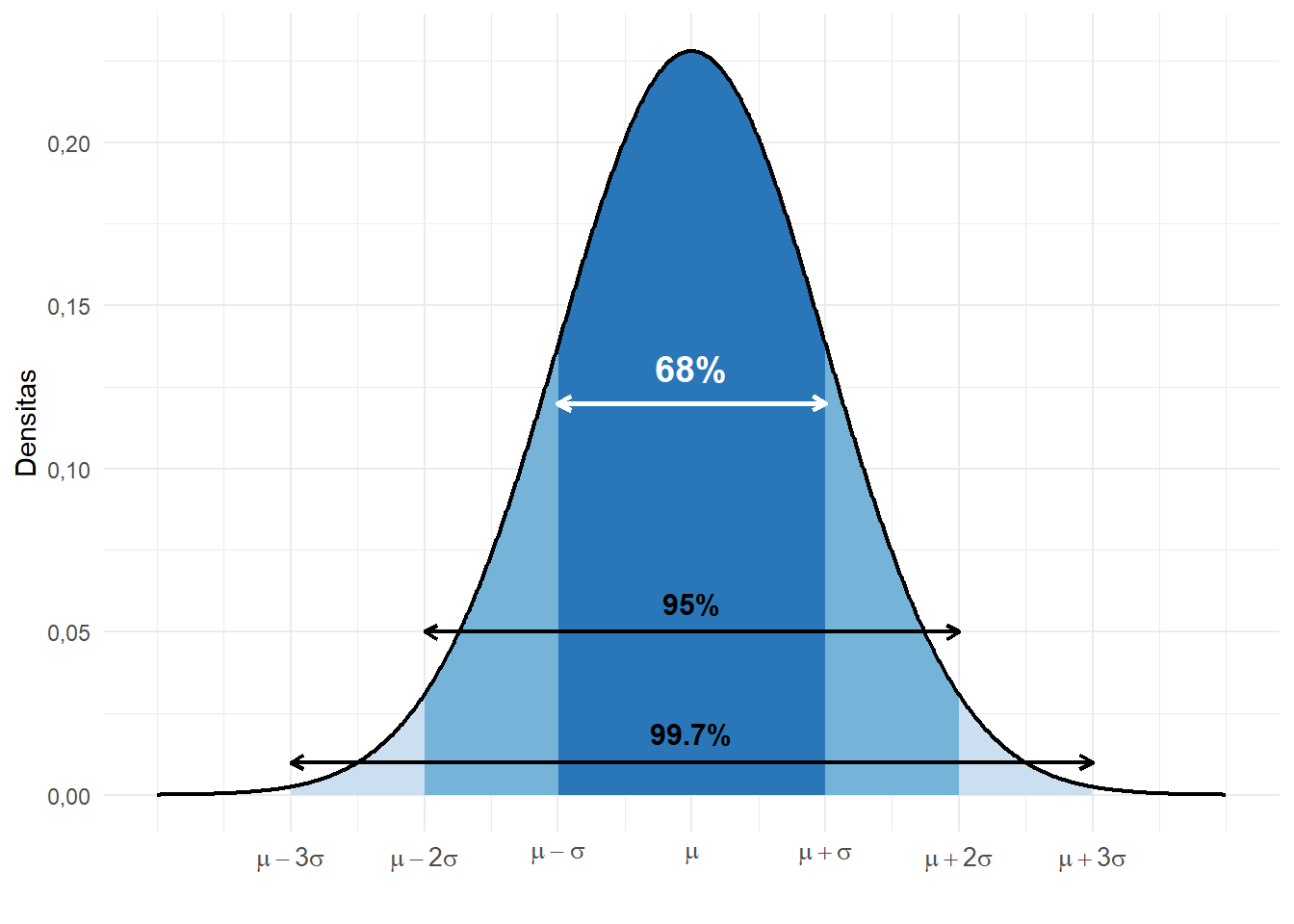
Gambar 5.11: Ilustrasi Aturan 68-95-99 (Aturan Empiris)
5.5.3 Distribusi \(t\)
Selain distribusi normal, dalam statistika inferensial kita juga mengenal distribusi \(t\). Distribusi \(t\) digunakan ketika kita ingin melakukan inferensi statistik pada populasi yang berukuran kecil (\(n < 120\)) atau ketika kita tidak mengetahui varians populasi. Distribusi ini dikembangkan oleh William Sealy Gosset pada awal abad ke-20 saat ia bekerja di pabrik bir Guinness di Dublin, di mana ia menggunakan nama samaran “Student” untuk menerbitkan temuannya (Ewing and Park 2020).
5.5.3.1 Karakteristik Visual dan Bentuk
Secara visual, distribusi \(t\) memiliki bentuk yang menyerupai lonceng dan simetris, mirip dengan distribusi normal standar (\(Z\)) (Healey 2021). Namun, terdapat perbedaan mendasar pada bagian ujung atau “ekor” kurvanya. Distribusi \(t\) cenderung lebih datar dan memiliki ekor yang lebih “berat” atau lebih tebal dibandingkan distribusi normal (Chan 2021b). Hal ini mencerminkan adanya ketidakpastian yang lebih besar karena penggunaan standar deviasi sampel (\(s\)) sebagai estimasi dari standar deviasi populasi (\(\sigma\)) yang tidak diketahui (Healey 2021).
5.5.3.2 Peran Derajat Bebas (Degrees of Freedom)
Bentuk spesifik dari kurva distribusi \(t\) sangat bergantung pada konsep yang disebut derajat bebas (degrees of freedom atau \(df\)). Derajat bebas merujuk pada jumlah nilai dalam sebuah distribusi yang bebas bervariasi setelah konstanta tertentu (seperti rata-rata) ditetapkan (Healey 2021). Untuk pengujian rata-rata sampel tunggal, derajat bebas dihitung dengan rumus:
\[df = N - 1\]
Di mana \(N\) adalah ukuran sampel (Healey 2021). Semakin besar ukuran sampel (dan otomatis semakin besar derajat bebasnya), distribusi \(t\) akan semakin mendekati bentuk distribusi normal standar (Healey 2021). Secara praktis, jika ukuran sampel melebihi 120, kedua distribusi ini dianggap identik (Healey 2021).
5.5.3.3 Formulasi Matematis
Dalam pengujian hipotesis, nilai \(t\) yang diperoleh (t-obtained) dihitung untuk menentukan apakah perbedaan antara rata-rata sampel dan rata-rata populasi signifikan secara statistik. Persamaannya adalah sebagai berikut (Ewing and Park 2020):
\[ t = \frac{\bar{X} - \mu}{s / \sqrt{N - 1}} \]
Di mana:
- \(\bar{X}\) adalah rata-rata sampel.
- \(\mu\) adalah rata-rata populasi yang dihipotesiskan.
- \(s\) adalah standar deviasi sampel.
- \(N - 1\) digunakan sebagai koreksi bias pada sampel kecil (Healey 2021).
Studi Kasus: Menghitung Nilai \(t\) Sampel Jarak Tempuh
Sebuah penelitian sebelumnya menduga bahwa rata-rata jarak tempat tinggal mahasiswa ITERA ke kampus adalah 5 km (\(\\mu = 5\)). Untuk menguji pernyataan tersebut, kita mengambil sampel acak sebanyak 20 mahasiswa (\(N = 20\)) dari pangkalan data mahasiswa ITERA dan menghitung jarak tempat tinggal mereka.
Dari sampel tersebut, didapatkan rata-rata sampel (\(\\bar{X}\)) sebesar 7,2 km dengan simpangan baku sampel (\(s\)) sebesar 3,8 km. Berapakah nilai statistik \(t\) untuk sampel ini?
Penyelesaian:
Berdasarkan data yang kita peroleh dari sampel, kita memiliki informasi sebagai berikut.
- \(\\bar{X} = 7,2\)
- \(\\mu = 5\)
- \(s = 3,8\)
- \(N = 20\)
- Derajat bebas (\(df\)) = \(N - 1 = 20 - 1 = 19\)
Kita dapat menghitung nilai \(t\) (t-obtained) menggunakan persamaan distribusi \(t\) yang sebelumnya telah dibahas:
\[ \\begin{align} t &= \\frac{\\bar{X} - \\mu}{s / \\sqrt{N - 1}} \\\\ &= \\frac{7,2 - 5}{3,8 / \\sqrt{20 - 1}} \\\\ &= \\frac{2,2}{3,8 / \\sqrt{19}} \\\\ &= \\frac{2,2}{3,8 / 4,3589} \\\\ &= \\frac{2,2}{0,8718} \\\\ &= 2,523 \\end{align} \]
Nilai \(t = 2{,}523\) menunjukkan bahwa rata-rata jarak sampel (7,2 km) berada pada 2,523 standard error di atas nilai rata-rata populasi yang diduga (5 km).
Untuk memberikan gambaran yang lebih jelas, berikut adalah visualisasi letak nilai rata-rata sampel kita di dalam kurva distribusi \(t\) dengan derajat bebas \(df = 19\).
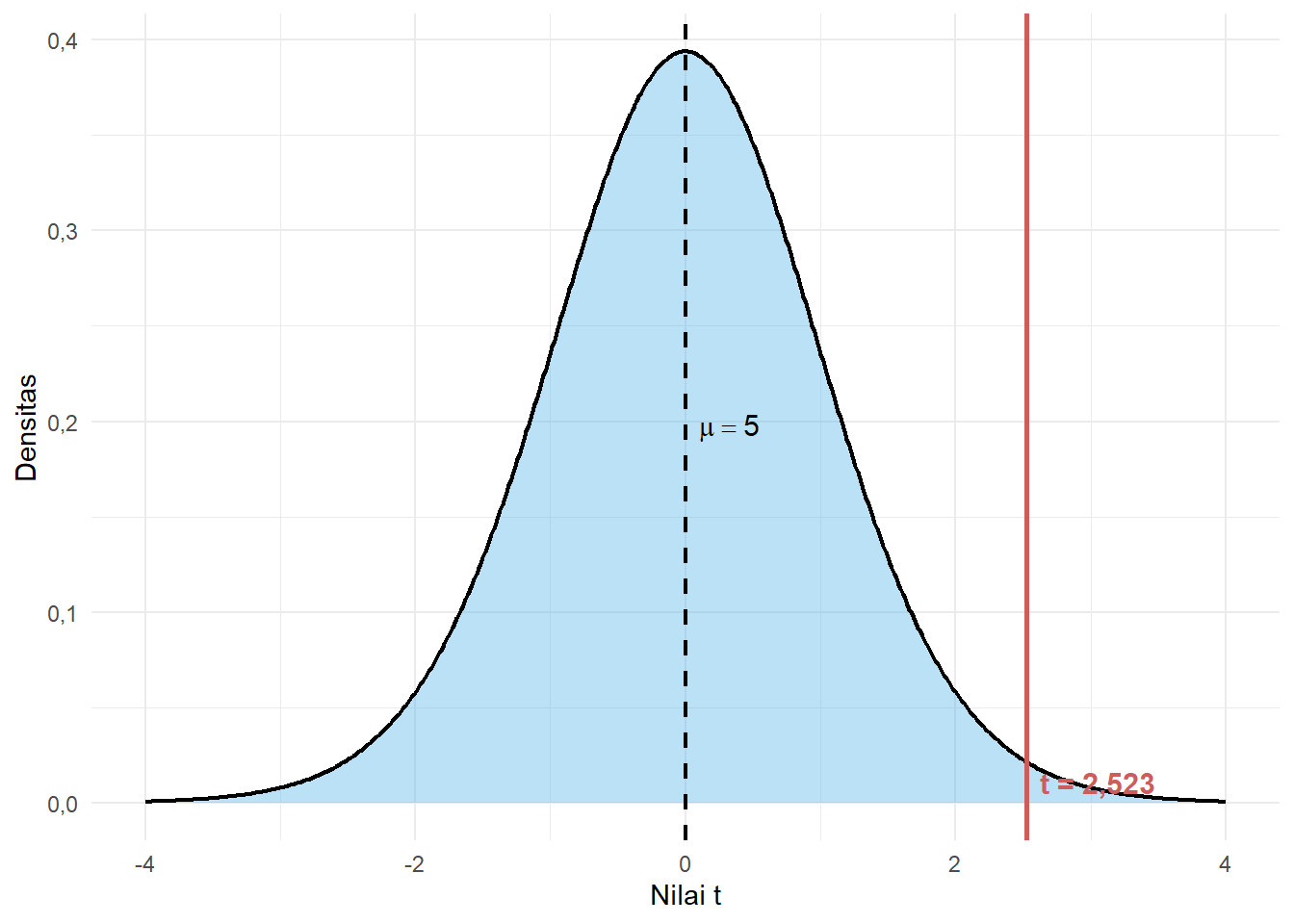
Gambar 5.12: Posisi Rata-rata Sampel pada Kurva Distribusi t (df = 19)
5.5.4 Distribusi Objek dan Distribusi Statistik
Distribusi objek atau distribusi sampel merujuk pada sebaran nilai data dari objek-objek yang menjadi sampel yang kita ambil. Dengan kata lain, distribusi ini menggambarkan variasi data individual setiap objek.
Di sisi lain, distribusi statistik atau distribusi hasil sampel (sampling distribution) adalah sebaran nilai statistik (misalnya rata-rata) dari suatu populasi yang berasal dari perhitungan statistik sampel-sampel yang diambil berulang kali dari populasi tersebut. Statistik yang dihitung biasanya dapat berupa proporsi atau rata-rata.
Mari pelajari kasus berikut untuk lebih memahami perbedaan antara distribusi objek dengan distribusi statistik.
Studi Kasus: Distribusi Objek vs Distribusi Statistik
Agar lebih mudah membayangkan perbedaan antara distribusi objek dan distribusi statistik, mari kita gunakan populasi kecil yang hanya terdiri dari 30 mahasiswa (diambil dari data ITERA). Kita akan melihat variabel Jarak Tempuh (km).
1. Distribusi Objek (Sebaran Data Individu)
Berikut adalah data populasi lengkap (N=30):
| ID | Jarak | ID | Jarak |
|---|---|---|---|
| 18 | 0,44 | 4 | 5,01 |
| 2 | 0,72 | 12 | 5,19 |
| 17 | 1,76 | 21 | 5,24 |
| 28 | 2,05 | 15 | 5,30 |
| 7 | 2,24 | 20 | 5,40 |
| 23 | 2,75 | 26 | 5,57 |
| 22 | 2,78 | 24 | 5,99 |
| 9 | 2,79 | 10 | 6,50 |
| 29 | 3,57 | 5 | 6,59 |
| 19 | 3,77 | 6 | 6,78 |
| 30 | 3,77 | 14 | 7,07 |
| 27 | 4,47 | 13 | 7,82 |
| 8 | 4,85 | 3 | 8,70 |
| 16 | 4,88 | 11 | 10,44 |
| 25 | 4,88 | 1 | 12,41 |
Rata-rata populasi adalah \(\mu = 4,99\) km dengan simpangan baku \(\sigma = 2,67\) km.
Sekarang, kita ambil 1 sampel berukuran \(n=10\) secara acak (Simple Random Sampling). Pengambilan menghasilkan sampel dengan ID 3, 9, 14, 17, 22, 23, 24, 25, 27, dan 30.
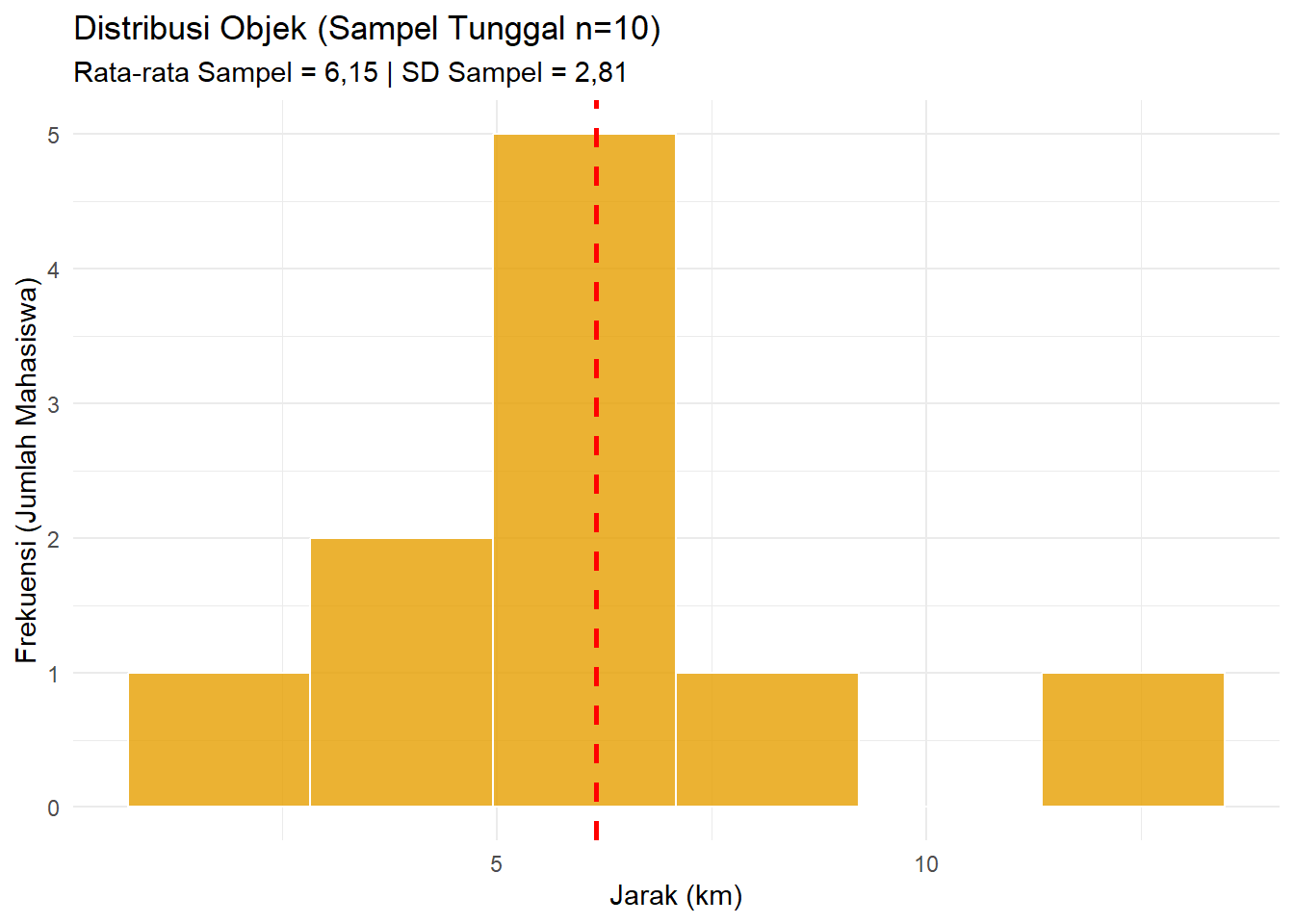
Gambar 5.13: Histogram Distribusi Objek (n=10)
Pada histogram di atas, sumbu Y (“Frekuensi”) menunjukkan jumlah mahasiswa yang memiliki jarak tempuh tertentu. Variasi datanya menggambarkan seberapa berbeda jarak antar individu.
2. Distribusi Statistik (Sebaran Rata-rata)
Sekarang, kita lakukan simulasi: kita mengambil sampel (\(n=10\)) dari populasi tersebut sebanyak 200 kali. Setiap kali ambil, kita catat rata-ratanya.
Berikut adalah 8 hasil pertama dari 200 pengambilan sampel:
| Pengambilan_Ke | Rata_Rata_Sampel |
|---|---|
| 1 | 3,79 |
| 2 | 4,72 |
| 3 | 4,7 |
| 4 | 4,62 |
| 5 | 6,76 |
| 6 | 5,94 |
| 7 | 3,89 |
| 8 | 3,82 |
| … | … |
Mari kita lihat histogram dari 200 rata-rata ini:
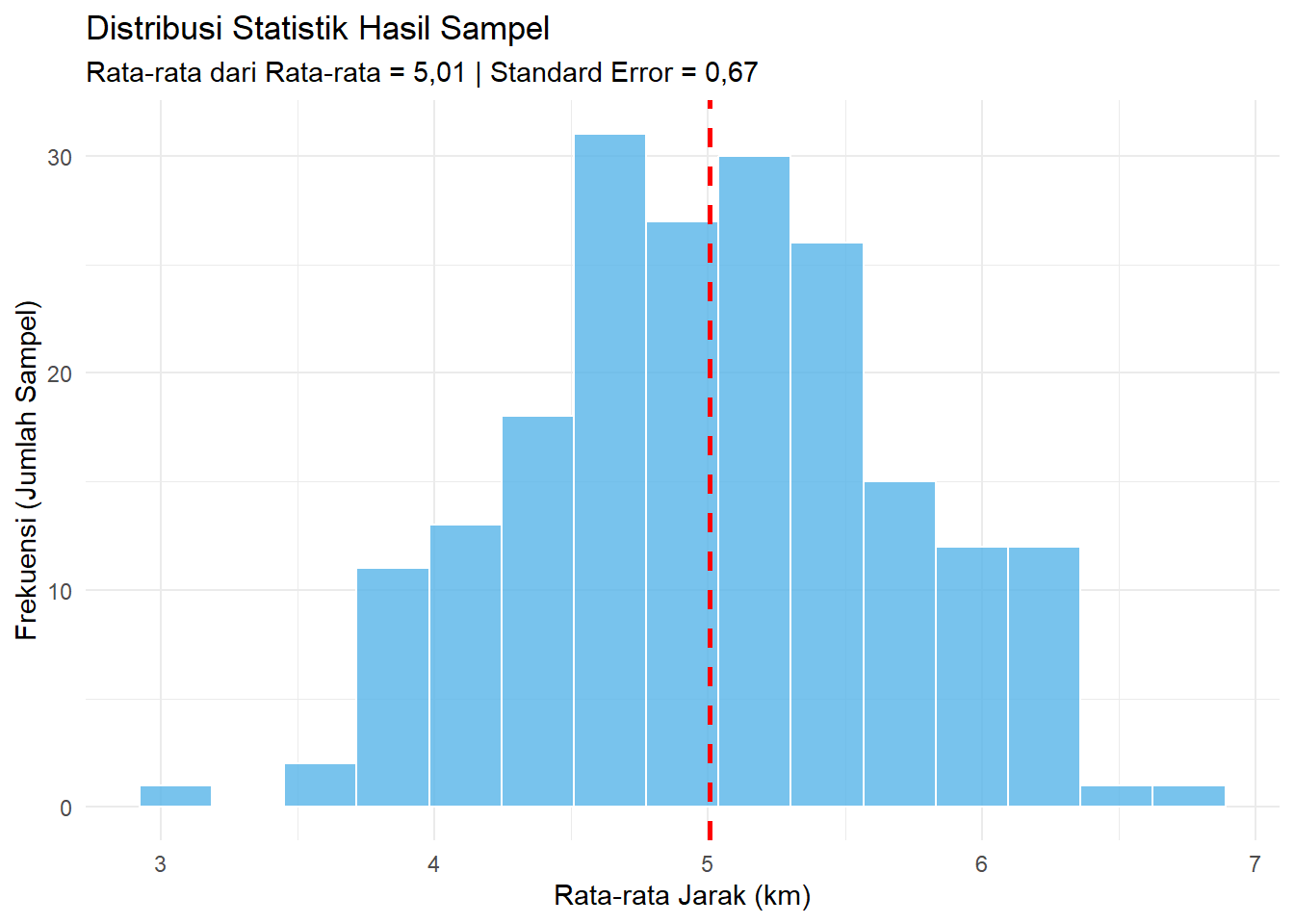
Gambar 5.14: Distribusi Statistik (200 Rata-rata)
Perhatikan perbedaan kedua histogram tersebut:
Distribusi objek: Pada distribusi objek, tinggi batang (nilai di sumbu Y) mencerminkan “jumlah orang atau frekuensi objek yang memiliki nilai-nilai yang ada di sumbu X”. Misalnya, objek yang memiliki nilai di antara 2,5 sampai 4,0 ada 4 buah (ID 23, 22, 9, dan 30), sementara 4,0 sampai 6,0 ada 2 objek (ID 27 dan 25).
Distribusi statistik: Pada distribusi statistik, tinggi batang mencerminkan frekuensi munculnya nilai rata-rata dari 200 kali pengambilan sampel sebanyak 10 objek. Jika kita kaitkan dengan probabilitas, maka tinggi batang mewakili tingkat kemungkinan suatu nilai rata-rata dihasilkan dari sampel yang berjumlah 10 objek.
Soal Evaluasi 7
STP-4.2 Suatu sampel pegawai ITERA berjumlah 286 orang yang mengukur jarak tempat tinggal mereka ke kampus menghasilkan rata-rata 7,90 km dan simpangan baku 6,42 km.
Jelaskan perbedaan distribusi objek dengan distribusi statistik berdasarkan kasus tersebut.
5.6 Teorema Limit Sentral
Tentu saja, di kehidupan nyata distribusi statistik dapat dikatakan tidak pernah ada. Sangat sulit untuk bisa mengambil sampel berkali-kali hingga sangat banyak. Ia hanyalah konsep teoritis untuk menjelaskan bagaimana suatu sampel bisa memiliki pola statistik sampel yang dapat memprediksi populasi. Dengan memahami pola prediksi tersebut, kita tidak perlu lagi menghimpun semua anggota populasi untuk menghitung parameter populasi. Cukup dengan mengumpulkan sampel tersebut, menghitung statistiknya, dan memperkirakan parameternya berdasarkan statistik tersebut.
Pola prediksi inilah yang dijelaskan oleh Teorema Limit Sentral (Central Limit Theorem). Teorema ini menjadi pijakan analisis inferensial karena memberikan dua jaminan penting:
jika ukuran sampel cukup besar (biasanya \(n \ge 30\)), distribusi statistik sampel akan berbentuk normal (lonceng simetris) apa pun bentuk populasi asalnya.
rata-rata dari distribusi statistik ini akan tepat sama dengan rata-rata populasi sebenarnya, dengan variasi yang semakin kecil seiring bertambahnya ukuran sampel. Ini adalah jaminan yang paling krusial dari teorema ini.
Kombinasi bentuk normal dan akurasi inilah yang memungkinkan kita melakukan estimasi dan uji statistik dengan percaya diri.
Berdasarkan teorema ini, kita dapat membagi analisis statistika inferensial menjadi analisis statistik inferensial parametrik dan nonparametrik. Analisis inferensial parametrik adalah analisis inferensial yang mengasumsikan bahwa populasi kita berdistribusi normal. Asumsi ini diuji dengan teknik pengujian kenormalan seperti uji Shapiro-Wilk atau P-P plot.
Studi Kasus: Simulasi Teorema Limit Sentral
Mari kita buktikan CLT dengan melakukan simulasi pengambilan sampel berulang. Katakanlah kita memiliki 428 mahasiswa sebagai populasi. Kita akan mengambil 1000 kali sampel berukuran 50 orang, lalu menghitung rata-ratanya dan memplot histogramnya.
Berikut adalah baris perintah untuk melakukan simulasi tersebut dalam R. Dataset yang digunakan dapat diakses pada tautan ini.
library(ggplot2)
library(gridExtra)
library(dplyr)
# Setup Ulang Populasi Besar (N=428) untuk CLT
data_itera <- read.csv("datasets/DataUtama_mhsITERA.csv", sep = ";")
data_populasi <- data_itera |>
mutate(jarak = jarak.km) |>
filter(!is.na(jarak))
# Hitung parameter populasi
mu <- mean(data_populasi$jarak)
N <- nrow(data_populasi)
# 1. Distribusi Populasi (Data Asli)
p1 <- ggplot(data_populasi, aes(x = jarak)) +
geom_histogram(bins = 30, fill = "gray", color = "black", alpha = 0.7) +
geom_vline(xintercept = mu, color = "red", size = 1) +
labs(title = paste0("Distribusi Populasi (N=", N, ")"), x = "Jarak (km)") +
theme_minimal()
# 2. Distribusi Statistik Sampel (Rata-rata dari 50 sampel yang diambil 1000 kali) --> SIMULASI
set.seed(999)
means_1000 <- replicate(1000, mean(sample(data_populasi$jarak, 50)))
df_means <- data.frame(means = means_1000)
p2 <- ggplot(df_means, aes(x = means)) +
geom_histogram(bins = 30, fill = "steelblue", color = "white", alpha = 0.9) +
geom_vline(xintercept = mean(means_1000), color = "red", size = 1) +
labs(title = "Distribusi Sampling (n=50, 1000x)", x = "Rata-rata Sampel") +
theme_minimal()
grid.arrange(p1, p2, ncol = 2)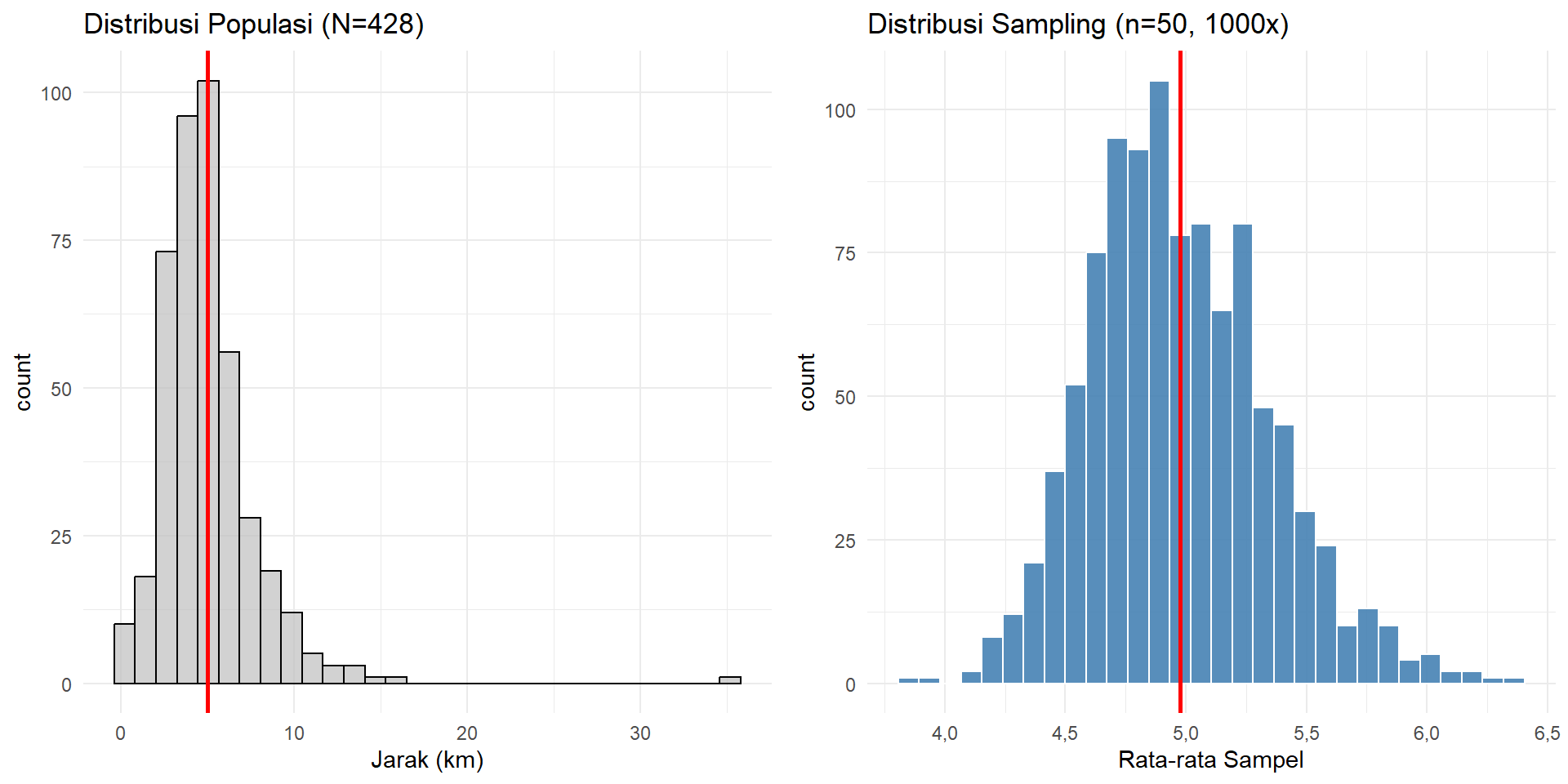
Gambar 5.15: Perbandingan Distribusi Populasi (Kiri) dan Distribusi Statistiknya (Kanan)
Gambar 5.15 menunjukkan distribusi objek populasi. Distribusi populasi (kiri) terlihat “miring” (skewed) ke kanan, artinya tidak normal. Namun, distribusi rata-rata sampelnya (kanan) berbentuk lonceng simetris yang hampir sempurna normal. Rata-rata dari distribusi statistik ini juga sangat dekat dengan rata-rata populasi sebenarnya (\(\mu = 5,01\)).
Studi Kasus: Efek Ukuran Sampel terhadap Variasi
Mari kita lanjutkan eksperimen kita. Apa yang terjadi jika kita mengubah ukuran sampel (\(n\)) yang kita ambil berulang-ulang tersebut? Kali ini kita akan membandingkan distribusi statistik yang dihasilkan dari pengambilan sampel berukuran \(n=30\) dengan \(n=100\).
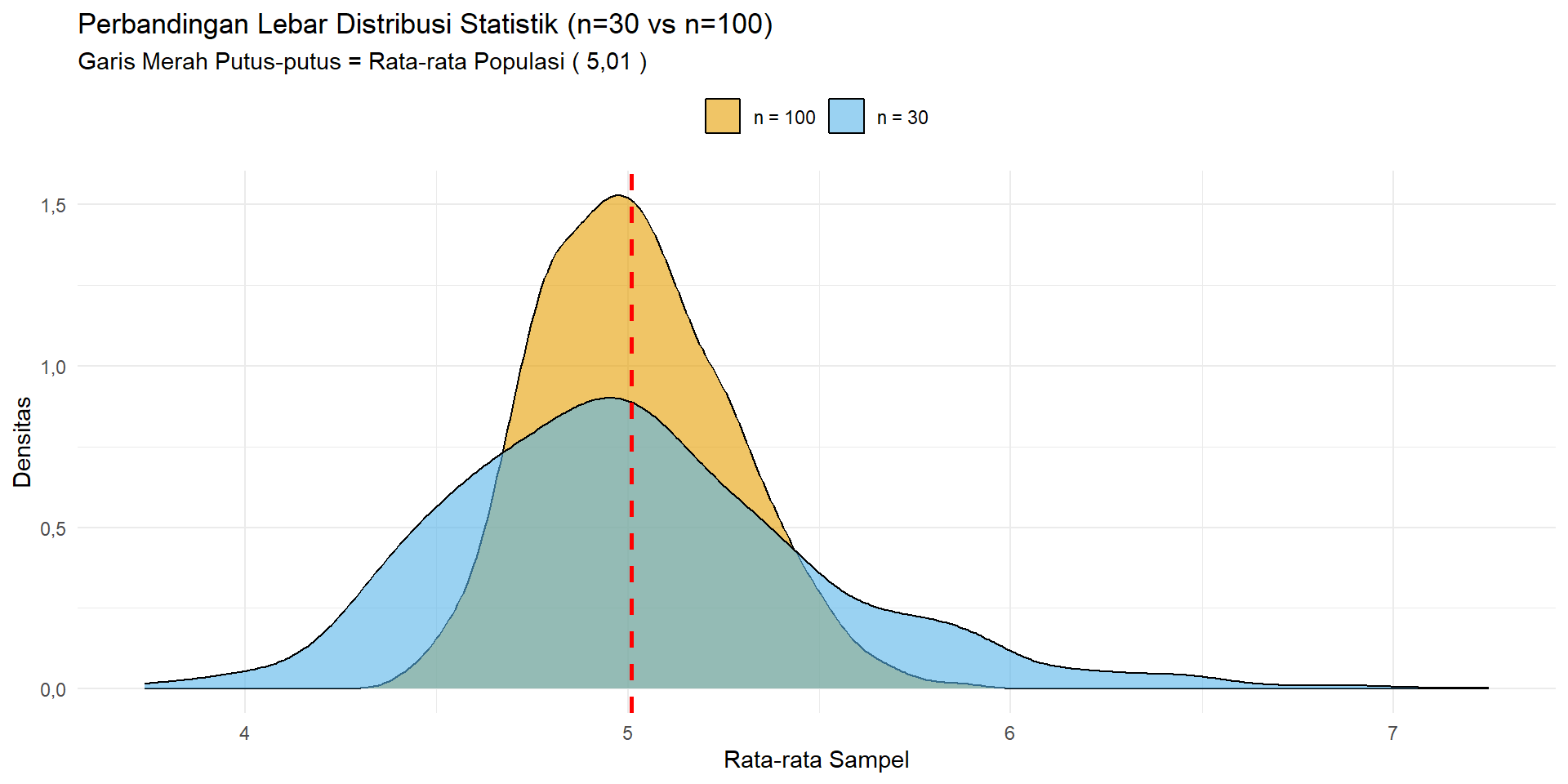
Gambar 5.16: Perbandingan Distribusi Statistik dengan Ukuran Sampel Berbeda
Perhatikan Gambar 5.16. Meskipun kedua kurva sama-sama berbentuk lonceng dan berpusat di rata-rata populasi (garis merah), kurva distribusi statistik untuk \(n=100\) (biru) jauh lebih “kurus” dan tinggi dibandingkan kurva \(n=30\) (kuning).
Ini menunjukkan bahwa semakin banyak sampel yang kita ambil dalam satu kali pengambilan (\(n\) semakin besar), maka variasi dari rata-rata yang kita peroleh akan semakin kecil. Artinya, rata-rata sampel kita akan semakin jarang meleset jauh dari rata-rata populasi sebenarnya. Dengan kata lain, memperbesar ukuran sampel akan meningkatkan peluang kita untuk mendapatkan hasil yang sangat mendekati kondisi populasi yang sebenarnya.
Soal Evaluasi 8
STP-4.2 Suatu sampel pegawai ITERA berjumlah 286 orang yang mengukur jarak tempat tinggal mereka ke kampus menghasilkan rata-rata 7,90 km dan simpangan baku 6,42 km.
Apakah kita dapat menggunakan teorema limit sentral dalam perhitungan probabilitas distribusi statistik sampel tersebut? Jelaskan jawaban Anda.
5.7 Menghitung Peluang Kemunculan Nilai Tertentu dari Distribusi Statistik yang Berbentuk Normal.
Pada subbab 5.5.2, kita telah belajar bahwa distribusi normal mempunyai aturan empiris atau aturan 68-95-99. Aturan ini berbicara tentang besar area di bawah kurva yang tetap berdasarkan jarak standar deviasi (SD) dari rata-rata (Healey 2021):
- \(\pm\) 1 SD mencakup sekitar 68,26% dari total kasus.
- \(\pm\) 2 SD mencakup sekitar 95,44% dari total kasus.
- \(\pm\) 3 SD mencakup sekitar 99,72% dari total kasus.
Sekarang kita akan menerapkan aturan empiris ini pada distribusi statistik yang berbentuk normal. Kita akan banyak menggunakan distribusi normal ini untuk menghitung probabilitas terjadinya–yang diwakili oleh besar area di bawah kurva distribusi normal–dari suatu nilai yang diminta, atau menentukan nilai yang menjadi pembatas suatu probabilitas.
Untuk itu, kita perlu memahami konsep tentang standard error dan nilai standar atau nilai Z (Z-score). Kedua konsep ini sangat krusial bagi kita untuk memudahkan kita membaca tabel nilai Z yang beguna untuk
5.7.1 Standard Error (SE)
Sebagaimana yang sudah kita pelajari, distribusi statistik berbeda dengan distribusi objek dalam hal nilai yang diukur. Jika distribusi objek mengukur nilai dari objek, maka distribusi statistik mengukur nilai dari sekumpulan objek yang diambil berulang-ulang dari populasi.
Dalam distribusi objek, lebar distribusi berkaitan dengan ukuran statistik deskriptif yang disebut standar deviasi atau simpangan baku. Simpangan baku menunjukkan ukuran jarak rata-rata penyimpangan nilai-nilai dalam distribusi terhadap rata-ratanya. Untuk penyegaran, rumusnya adalah sebagai berikut.
\[ \begin{align} \text{Simpangan Baku} &= \sqrt{\text{Variansi}}\\ &=\sqrt{\frac{\sum_{i=1}^{n}(x_i - \bar{x})^2}{n}} \tag{5.1} \end{align} \]
Di sisi lain, dalam distribusi statistik simpangan bakunya punya sebutan lain, yakni standard error (SE). Standard error pada hakikatnya adalah adalah ukuran jarak statistik sampel dari parameter populasi. Ingat kembali bahwa rata-rata dari distribusi statistik adalah nilai parameter populasinya. Semakin kecil SE, semakin presisi estimasi sampel kita terhadap parameter populasi. Secara matematis, standard error dihitung dari simpangan baku sampel kita dengan rumus berikut.
\[ \begin{align} \text{SE} &=\frac{\sigma}{\sqrt{n}} \tag{5.2} \end{align} \]
Dengan \(\sigma\) adalah simpangan baku populasi dan \(n\) adalah ukuran sampel.
Jika \(\sigma\) tidak diketahui, kita gunakan simpangan baku sampel (\(s\)) sebagai estimasi, sehingga Persamaan (5.2) menjadi:
\[ \begin{align} \text{SE} &=\frac{s}{\sqrt{n}} \tag{5.3} \end{align} \]
PENTING
Dalam beberapa sumber, seperti Healey (2021), perhitungan standard error yang menggunakan estimasi dari simpangan baku seperti Persamaan (5.3) menggunakan bentuk yang dikoreksi, yakni dengan cara mengurangkan 1 dari nilai ukuran sampelnya, sehingga persamaannya menjadi:
\[ \begin{align} \text{SE} &=\frac{s}{\sqrt{n-1}} \tag{5.4} \end{align} \]
Yang mana yang betul? Karena keduanya sama-sama disebutkan dalam banyak literatur, di sini yang perlu kita perhatikan adalah konsistensi kita dalam penggunaan salah satunya.
Studi Kasus: Menghitung Standard Error
Misalkan kita mengambil satu sampel acak berukuran \(n=100\) mahasiswa dari populasi.
Dari sampel ini, kita peroleh rata-rata jarak \(\bar{x} = 5,16\) km. Kita tahu simpangan baku populasi \(\sigma = 2,82\) km. Maka Standard error adalah:
\[ \begin{align} SE &=\frac{s}{\sqrt{n}}\\ &= \frac{2,82}{\sqrt{100}} \\ &= 0,2817 \end{align} \]
Nilai ini memberitahu kita bahwa rata-rata sampel kita (5,16) diperkirakan menyimpang sekitar \(\pm 0,28\) km dari rata-rata populasi sebenarnya.
Soal Evaluasi 9
STP-4.2 Suatu sampel pegawai ITERA berjumlah 286 orang yang mengukur jarak tempat tinggal mereka ke kampus menghasilkan rata-rata 7,90 km dan simpangan baku 6,42 km.
Berapakah standard error dari distribusi statistik sampel tersebut?
5.7.2 Nilai Standar (Z-Score)
Z-score menunjukkan posisi suatu nilai dalam sumbu X distribusi normal jika rata-rata distribusi tersebut dibuat 0 dan simpangan bakunya dibuat 1. Untuk distribusi objek, rumusnya adalah:
\[ \begin{align} Z = \frac{x - \mu}{\sigma} \tag{5.5} \end{align} \]
Dengan \(x\) adalah nilai dalam distribusi normal yang akan kita konversi, \(\mu\) melambangkan rata-rata distribusi, dan \(\sigma\) melambangkan simpangan baku distribusi.
Kegunaan dari perhitungan nilai terstandar atau nilai Z ini adalah kita dapat menyatakan nilai statistik yang menggunakan skala berbeda-beda menjadi nilai yang sama. Hal ini memungkinkan kita membandingkan nilai-nilai tersebut dengan setara, walaupun skala atau satuannya tidak sama.
Studi Kasus: Menghitung Z-Score Suatu Nilai
Dalam sebuah sampel yang berjumlah 100 orang, kita mempunyai distribusi biaya perjalanan dengan rata-rata (\(\mu\)) 50.000 dan simpangan baku (\(\sigma\)) 10.000. Jika seseorang menghabiskan biaya perjalanan sebesar \(x = 65.000\). Berapakah Z-score pengeluarannya?
Jawaban:
Z-score nilainya dihitung sebagai berikut:
\[ \begin{align} Z &= \frac{x - \mu}{\sigma} \\ &= \frac{65.000 - 50.000}{10.000} \\ &= \frac{15.000}{10.000} \\ &= 1,5 \end{align} \]
Nilai \(Z = 1,5\) berarti biaya perjalanan orang tersebut berada 1,5 kali simpangan baku di atas rata-rata populasi.
Sekarang, mari pertimbangkan variabel lain dari sampel yang sama untuk melihat bagaimana Z-score memungkinkan kita membandingkan dua unit pengukuran yang berbeda.
Misalkan dari 100 orang tersebut, kita juga mempunyai distribusi jarak tempuh dengan rata-rata (\(\mu\)) 10 km dan simpangan baku (\(\sigma\)) 2 km. Jika orang yang sama tadi harus menempuh jarak sejauh \(x = 13\) km, berapakah Z-score jarak tempuhnya?
Jawaban:
Z-score nilainya dihitung sebagai berikut:
\[ \begin{align} Z &= \frac{x - \mu}{\sigma} \\ &= \frac{13 - 10}{2} \\ &= \frac{3}{2} \\ &= 1,5 \end{align} \]
Meskipun menggunakan satuan yang berbeda (biaya dalam Rupiah versus jarak dalam kilometer), nilai Z-score pada kedua variabel tersebut ternyata sama (\(Z=1,5\)). Hal ini berarti biaya perjalanan sebesar 65.000 dan jarak tempuh sejauh 13 km memiliki “posisi” relatif yang sama, yakni sama-sama melampaui 1,5 simpangan baku di atas rata-ratanya masing-masing. Inilah wujud nyata bagaimana Z-score menyetarakan nilai-nilai dengan satuan yang berbeda ke dalam satu ukuran standar.
Jika kita menggunakan konsep Z-Score tersebut pada distribusi statistik, persamaan (5.5) akan berubah dari \(x\) menjadi \(\bar{x}\) dan \(\sigma\) menjadi \(SE\):
\[ \begin{align} Z = \frac{\bar{x} - \mu}{SE} \tag{5.6} \end{align} \]
Dengan \(\bar{x}\) adalah rata-rata sampel yang kita miliki, \(\mu\) adalah rata-rata populasi (parameter) yang kita jadikan sebagai patokan, dan \(SE\) adalah standard error yang dihitung dengan persamaan (5.3) atau (5.4), sehingga persamaan (5.6) sama saja bentuknya dengan:
\[ \begin{equation} Z = \frac{\bar{x} - \mu}{s/\sqrt{n}} \tag{5.6} \end{equation} \]
Studi Kasus: Menghitung Z-Score Rata-rata Sampel
Melanjutkan kasus distribusi biaya perjalanan sebelumnya, dengan menggunakan nilai rata-rata, simpangan baku, dan ukuran sampel yang sama, asumsikan kita mengetahui bahwa rata-rata biaya perjalanan populasi (\(\mu\)) sebesar 52.000. Berapakah nilai Z-score dari rata-rata sampel tersebut?
Jawaban:
Pertama-tama, hitung terlebih dahulu nilai standard error (SE)-nya:
\[ \begin{align} SE &= \frac{s}{\sqrt{n}} \\ &= \frac{10.000}{\sqrt{100}} \\ &= \frac{10.000}{10} \\ &= 1.000 \end{align} \]
Selanjutnya, gunakan nilai SE tersebut untuk menghitung nilai Z-score dari rata-rata sampel yang kita peroleh:
\[ \begin{align} Z &= \frac{\bar{x} - \mu}{SE} \\ &= \frac{50.000 - 52.000}{1.000} \\ &= \frac{-2.000}{1.000} \\ &= -2,0 \end{align} \]
Nilai \(Z = -2,0\) ini berarti angka rata-rata sampel yang kita himpun tersebut (\(\bar{x} = 50.000\)) menduduki posisi 2 simpangan baku (atau 2 kali standard error) di bawah asumsi parameter rata-rata populasinya (\(\mu = 52.000\)). Dalam hal ini, Z-score mencerminkan rentang penyimpangan sampel terhadap populasinya: semakin jauh nilai Z-score dari angka nol, semakin jauh sampel kita menyimpang. Jika sampel kita ternyata dikategorikan “terlalu menyimpang”, ada kemungkinan terjadinya bias ketika kita menghimpun sampel ke lapangan, atau asumsi kita mengenai rata-rata populasi tersebutlah yang justru keliru.
Soal Evaluasi 10
STP-4.2 Suatu sampel pegawai ITERA berjumlah 286 orang yang mengukur jarak tempat tinggal mereka ke kampus menghasilkan rata-rata 7,90 km dan simpangan baku 6,42 km.
Jika diketahui parameter (rata-rata jarak tempat tinggal seluruh pegawai ITERA) sebesar 7,5 km, hitunglah nilai standar (z-score) sampel tersebut. Ulaslah hasil perhitungan Anda secara analitik berdasarkan konsep yang sudah Anda pelajar.
5.7.3 Menentukan Probabilitas Terjadinya Suatu Nilai
Probabilitas terjadinya suatu nilai dalam distribusi statistik yang berbentuk normal ditunjukkan oleh luasan area di bawah kurva distribusi tersebut. Luasan area di bawah kurva distribusi statistik ini dapat dihitung dengan terlebih dahulu menentukan nilai Z-score dari nilai tersebut.
Karena kurva distribusi normal bersifat kontinu, probabilitas terjadinya tepat satu nilai spesifik secara pasti (misalnya tepat 50.000) pada dasarnya dianggap nol. Oleh sebab itu, saat kita membicarakan probabilitas pada distribusi normal, kita harus selalu merujuk pada probabilitas dalam suatu rentang nilai. Ini berarti kita memerlukan rentang yang dibatasi oleh dua nilai (batas bawah dan batas atas), yang kemudian masing-masing harus dikonversikan menjadi dua nilai Z-score.
Untuk dapat menghitung probabilitas luasan di antara dua nilai Z-score ini, kita dapat memanfaatkan tabel statistik yang memuat nilai probabilitas kumulatif untuk setiap nilai Z-score. Tabel ini biasanya disajikan bersama ilustrasi area yang dimaksud seperti berikut.
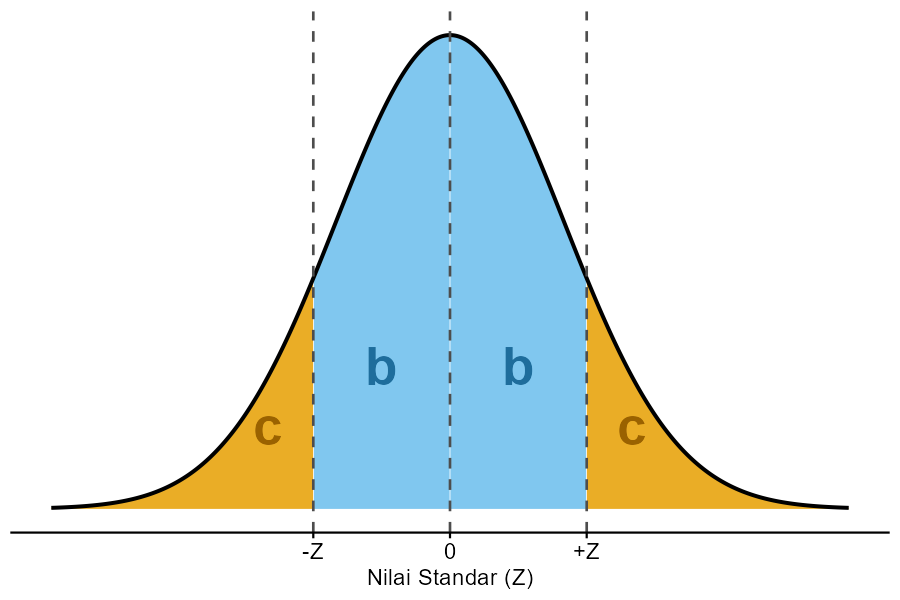
Gambar 5.17: Ilustrasi area b (kiri) dan c (kanan) pada distribusi normal. Area b dan c masing-masing melambangkan probabilitas nilai-nilai yang berada di luar rentang nilai yang diamati.
Beberapa contoh tabel yang dapat kita gunakan adalah seperti yang disertakan dalam Healey (2021) atau seperti yang disajikan Stat Calculators berikut.
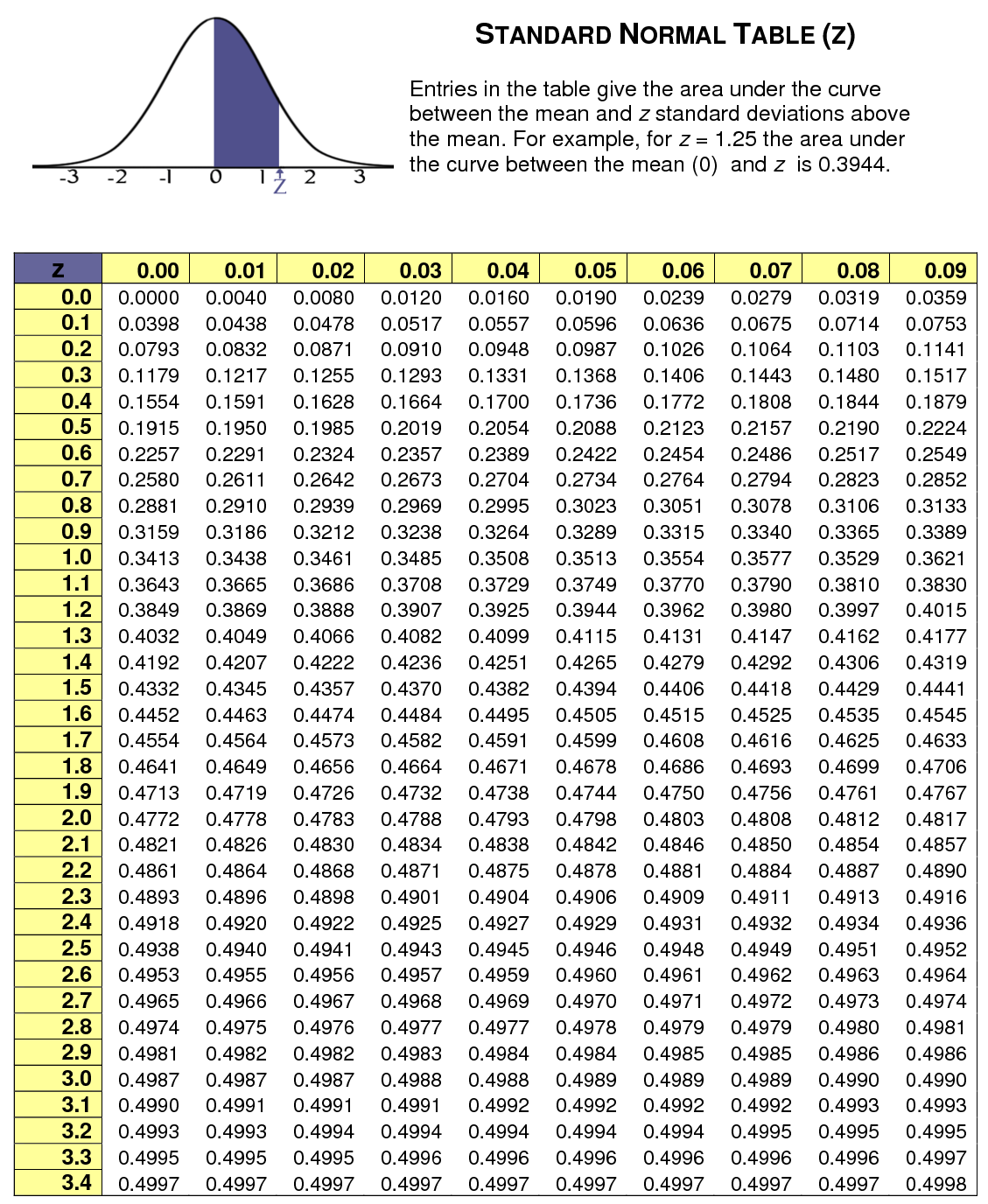
Gambar 5.18: Contoh tabel Z-score.
Dalam perangkat lunak statistik seperti R, kita dapat memanfaatkan fungsi pnorm() untuk menghitung probabilitas luasan di antara dua nilai Z-score ini.
Studi Kasus: Probabilitas Ditemukannya Suatu Sampel dengan Rata-rata Tertentu Dibandingkan dengan Rata-rata Populasi
Dengan sampel berukuran 100 orang yang memiliki rata-rata \(\bar{x} = 51.500\) dan standard error \(SE = 1.000\), berapakah probabilitas sampel tersebut ditemukan bila acuan kita adalah rata-rata populasi (\(\mu = 52.000\))?
Jawaban:
Kita perlu menghitung Z-score untuk \(\bar{x}=51.500\) terlebih dahulu:
\[ \begin{align} Z &= \frac{51.500 - 52.000}{1.000} \\ &= \frac{-500}{1.000} \\ &= -0,5 \end{align} \]
Sekarang kita memiliki dua singkapan tiang batas, yakni mulai dari \(Z = -0,5\) hingga \(Z = 0,0\) (rata-rata populasi). Kita dapat menggunakan tabel Z-score untuk menentukan probabilitas luasan di antara kedua nilai tersebut. Sebagai contoh, kita akan menggunakan Gambar 5.17.
Pertama, kita perlu memperhatikan ilustrasi distribusi yang ada di pojok kiri atas tabel tersebut. Area yang diwarnai biru pada gambar tersebut menunjukkan area b dari ilustrasi kita (Gambar 5.17, yaitu luasan dari \(Z = 0\) hingga suatu nilai \(Z\) positif tertentu. Karena distribusi normal bersifat simetris, luasan area di rentang \(Z = 0\) hingga \(Z = -0,5\) (yang kita cari) nilainya sama dengan luasan area di rentang \(Z = 0\) hingga \(Z = 0,5\) (positif).
Untuk membaca tabel, kita perlu mengambil nilai absolut dari \(Z\), yakni \(|Z| = 0,5\). Nilai ini dibaca dengan cara:
- Cari baris yang sesuai dengan angka puluhan dari \(Z\), yakni baris 0,5.
- Pada baris tersebut, pilih kolom yang sesuai dengan angka satuan kedua (angka di belakang desimal kedua), yakni kolom 0,00 karena \(Z = -0,50\) (tidak ada digit kedua).
- Nilai yang tercantum pada sel tersebut adalah 0,19146.
Nilai 0,19146 ini adalah probabilitas area b, yaitu probabilitas bahwa rata-rata sampel kita jatuh di antara \(\bar{x} = 51.500\) (\(Z = -0,5\)) dan \(\mu = 52.000\) (\(Z = 0\)). Dengan kata lain, ada sekitar 19,1% peluang sampel acak kita akan menghasilkan rata-rata di antara rentang 51.500 dan 52.000.
5.7.4 Menentukan Nilai yang Menjadi Pembatas Suatu Probabilitas
Terdapat saatnya kita bekerja secara berkebalikan: kita sudah menetapkan batasan luasan persentase atau target probabilitas di awal, lalu ingin mengetahui berapa sebenarnya nilai konkret (\(X\) tunggal ataupun \(\bar{x}\) rata-rata sampel) dari batas tersebut.
Langkah yang dapat kita terapkan adalah mencari nilai Z-score yang bersesuaian dengan persentase probabilitas kumulatif yang dituju. Nilai tersebut didapatkan dengan melihat tabel Z-score atau dengan memakai fungsi R, yakni qnorm().
Setelah nilai \(Z\)-nya diketahui, kita dapat mengembalikannya menjadi nilai \(X\) atau \(\bar{x}\) sesuai konteks kasus kita dengan memanipulasi secara aljabar rumus konversi Z-score untuk mengembalikan rupa Z-score menuju skala aslinya:
Untuk distribusi objek: \(X = \mu + Z \cdot \sigma\)
Untuk distribusi statistik: \(\bar{x} = \mu + Z \cdot SE\)
Studi Kasus: Menentukan Batas Biaya Perjalanan Ekstrem (Distribusi Objek)
Apabila rata-rata biaya perjalanan mahasiswa per bulan dalam satu populasi adalah \(\mu = 50.000\) dengan simpangan baku \(\sigma = 10.000\), berapakah batas pengeluaran biaya perjalanan individu yang termasuk golongan 5% orang berbiaya hidup tertinggi di kampus tersebut?
Jawaban:
Pertama, kita harus memahami konteks pertanyaan dari soal. Frasa “golongan 5% orang berbiaya hidup tertinggi” berarti bahwa jika kita nyatakan dalam bentuk grafik distribusi normal, maka area tersebut berada di bagian c di sebelah kanan yang besarnya 5% atau 0,05 (Gambar 5.19).
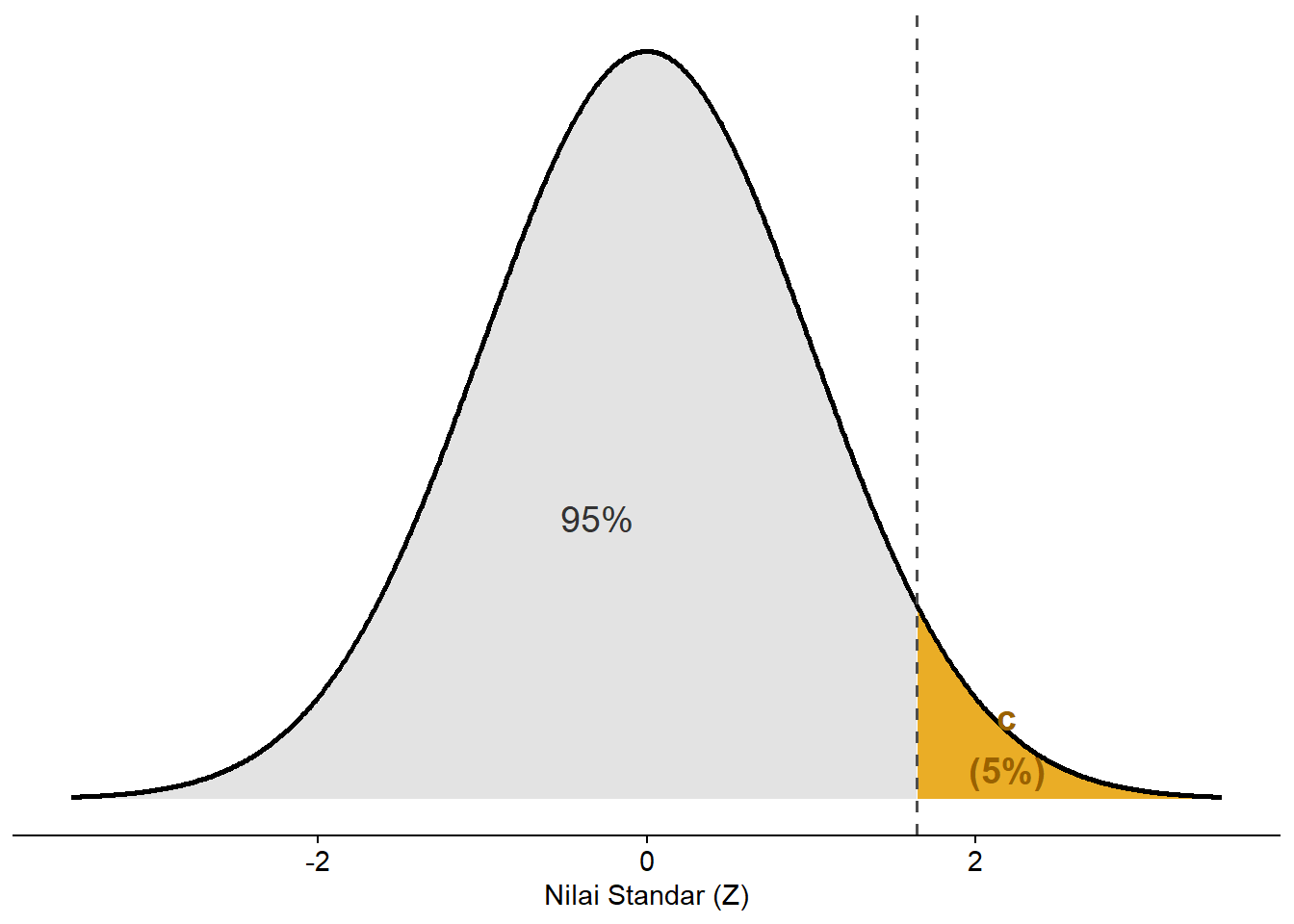
Gambar 5.19: Ilustrasi area c (ekor kanan) sebesar 5% pada distribusi normal.
Kedua, kita perlu memperhatikan area yang diwarnai biru pada Gambar 5.18. Area tersebut sebenarnya adalah area b di sebelah kanan dengan besar \(95%-50%=45%\) atau 0,45. Dengan demikian, kita perlu mencari nilai \(Z\) yang sesuai dengan proporsi 0,45.
Ketiga, kita akan cari nilai yang paling mendekati dengan 0,45 di sel-sel tabel pada Gambar 5.18. Didapatkan nilai \(Z = 1,64\) (baris 1,6 dan kolom 0,04) atau \(Z = 1,65\) (baris 1,6 dan kolom 0,05). Kita ambil nilai \(Z = 1,64\).
Keempat, jabarkan kembali variabel \(Z\) ini (berkisar 1,64) ke unit mata uang yang senyata-nyatanya:
\[ \begin{align} x &= 50.000 + (1,64 \cdot 10.000) \\ &= 50.000 + 16.400 \\ &= 66.450 \end{align} \]
Ini membeberkan simpulan bahwa seorang mahasiswa akan tergolong di klaster “5% mahasiswa dengan perjalanan kampus tereksklusif” asalkan ia rutin mengeluarkan paling tidak Rp66.450 ribu per bulan.
Soal Evaluasi 11
STP-4.2 Suatu sampel pegawai ITERA berjumlah 286 orang yang mengukur jarak tempat tinggal mereka ke kampus menghasilkan rata-rata 7,90 km dan simpangan baku 6,42 km.
Hitunglah seberapa sering sampel-sampel yang nilainya lebih kecil dari statistik sampel kita (rata-rata jarak 7,9 km) ditemukan. Lengkapi penjelasan Anda dengan ilustrasi grafik distribusi normalnya.
Petunjuk:
‘seberapa sering’ merujuk pada probabilitas.
perhatikan betul frasa ‘lebih kecil’ pada soal dan kaitkan dengan posisi area yang diwarnai seperti pada Gambar 5.17.