Bab 6 Estimasi Parameter
Capaian Pembelajaran
Setelah mempelajari bab ini, Anda diharapkan mampu memaknai interval kepercayaan estimasi sebuah parameter STP-5.1.
Estimasi parameter adalah teknik dalam statistika inferensial untuk memperkirakan nilai karakteristik populasi (parameter) berdasarkan data sampel (statistik) (Healey 2021; Tjokropandojo et al. 2021). Konsep dasar yang akan kita pelajari di antaranya:
- perbedaan antara statistik dan parameter,
- estimasi titik dan estimasi rentang, serta
- tingkat kepercayaan (confidence level).
Selanjutnya, konsep-konsep dasar ini menjadi dasar untuk mempelajari perhitungan estimasi parameter untuk proporsi dan rata-rata, serta interpretasi hasil estimasi.
6.1 Statistik vs. Parameter
Dalam statistika, kita akan sering menjumpai dua istilah penting, yaitu statistik dan parameter. Keduanya sama-sama merupakan ukuran kuantitatif yang digunakan untuk menggambarkan karakteristik data. Akan tetapi, perbedaannya terletak pada sumber datanya. Statistik diperoleh dari data sampel, sedangkan parameter adalah ukuran yang menggambarkan kondisi populasi secara keseluruhan (Tjokropandojo et al. 2021).
Karena parameter adalah ukuran untuk populasi, mengukurnya hanya bisa dilakukan dengan melibatkan seluruh populasi, yang disebut juga sensus. Karena sulit dilakukan, maka statistik digunakan untuk mengestimasi parameter.
Cara menyatakan ukuran statistik dan parameter, yakni menggunakan simbol-simbol matematis (Healey 2021), disajikan dalam tabel berikut.
| Ukuran | Statistik (Sampel) | Parameter (Populasi) |
|---|---|---|
| Rata-rata | \(\bar{x}\) | \(\mu\) |
| Simpangan baku | \(s\) | \(\sigma\) |
| Variansi | \(s^2\) | \(\sigma^2\) |
| Proporsi | \(\hat{p}\) | \(P\) |
| Jumlah nilai | \(x\) | \(X\) |
| Ukuran observasi | \(n\) | \(N\) |
Studi Kasus: Statistik vs Parameter
Mengingat kembali studi kasus pada bab sebelumnya, diketahui populasi seluruh mahasiswa aktif ITERA pada pertengahan tahun 2023 berjumlah 18.877 orang. Namun, karena keterbatasan biaya dan waktu, survei hanya dilakukan terhadap sebagian mahasiswa, yaitu sebanyak 428 orang sebagai sampel.
Misalkan kita ingin mengetahui rata-rata usia para mahasiswa tersebut. Dengan menghitung usia 428 responden tersebut, kita akan memperoleh rata-rata usianya sebesar 20,90 tahun. Angka ini merupakan sebuah statistik karena dihitung berdasarkan data sampel. Kita akan menggunakan simbol \(\bar{x}\) untuk menerangkan rata-rata sampel ini, sehingga \(\bar{x} = 20,90\) tahun.
Lalu, apa parameter dalam kasus ini? Parameternya adalah nilai rata-rata usia yang sebenarnya dari keseluruhan 18.877 mahasiswa aktif ITERA tersebut. Angka sesungguhnya ini kita simbolkan dengan \(\mu\). Karena parameter hanya bisa diketahui dari sensus terhadap seluruh populasi, nilai \(\mu\) ini tidak akan pernah kita ketahui persis jika sensus tidak pernah dilakukan.
Di sinilah statistik digunakan: kita memakai nilai statistik sampel (\(\bar{x} = 20,90\)) sebagai alat ukur untuk memperkirakan atau mengestimasi besaran parameter populasi (\(\mu\)).
6.2 Estimasi Titik vs. Estimasi Rentang
Karena kita jarang mengetahui nilai parameter dan lebih sering bisa memperoleh statistik, maka nilai parameter kita perkirakan dari nilai statistik. Proses menghasilkan perkiraan ini disebut estimasi. Estimasi berarti memperkirakan nilai parameter (populasi) berdasarkan hasil perhitungan statistik (sampel). Terdapat dua jenis estimasi yang umum digunakan, yaitu estimasi titik dan estimasi rentang (Tjokropandojo et al. 2021).
6.2.1 Estimasi Titik
Estimasi titik (point estimate) adalah estimasi nilai suatu parameter hanya dengan satu angka tunggal saja. Angka ini dihasilkan dari statistik sampel yang kita kumpulkan (Kachigan 1986).
Ciri utama estimasi titik adalah ia hanya terdiri dari satu nilai tunggal. Karena hanya memiliki satu nilai saja, kemungkinan kesalahannya sangat besar, karena sangat mungkin nilai tersebut berbeda jauh dari parameter yang sebenarnya.
Studi Kasus: Keterbatasan Estimasi Titik
Melanjutkan contoh sebelumnya, estimasi titik dari rata-rata usia mahasiswa ITERA adalah sebesar 20,90 tahun. Angka 20,90 tahun ini kita peroleh dari 428 responden, lalu kita gunakan sebagai penduga untuk parameter rata-rata usia seluruh mahasiswa ITERA (\(\mu\)).
Namun, kita tidak bisa memastikan apakah benar rata-rata populasi seluruh mahasiswa tepat sama dengan 20,90 tahun. Mungkin saja rata-rata populasi sebenarnya (parameter) adalah mendekati 20,50 tahun, 21,40 tahun, atau nilai lainnya. Hal inilah yang digambarkan pada Gambar 6.1 berikut.
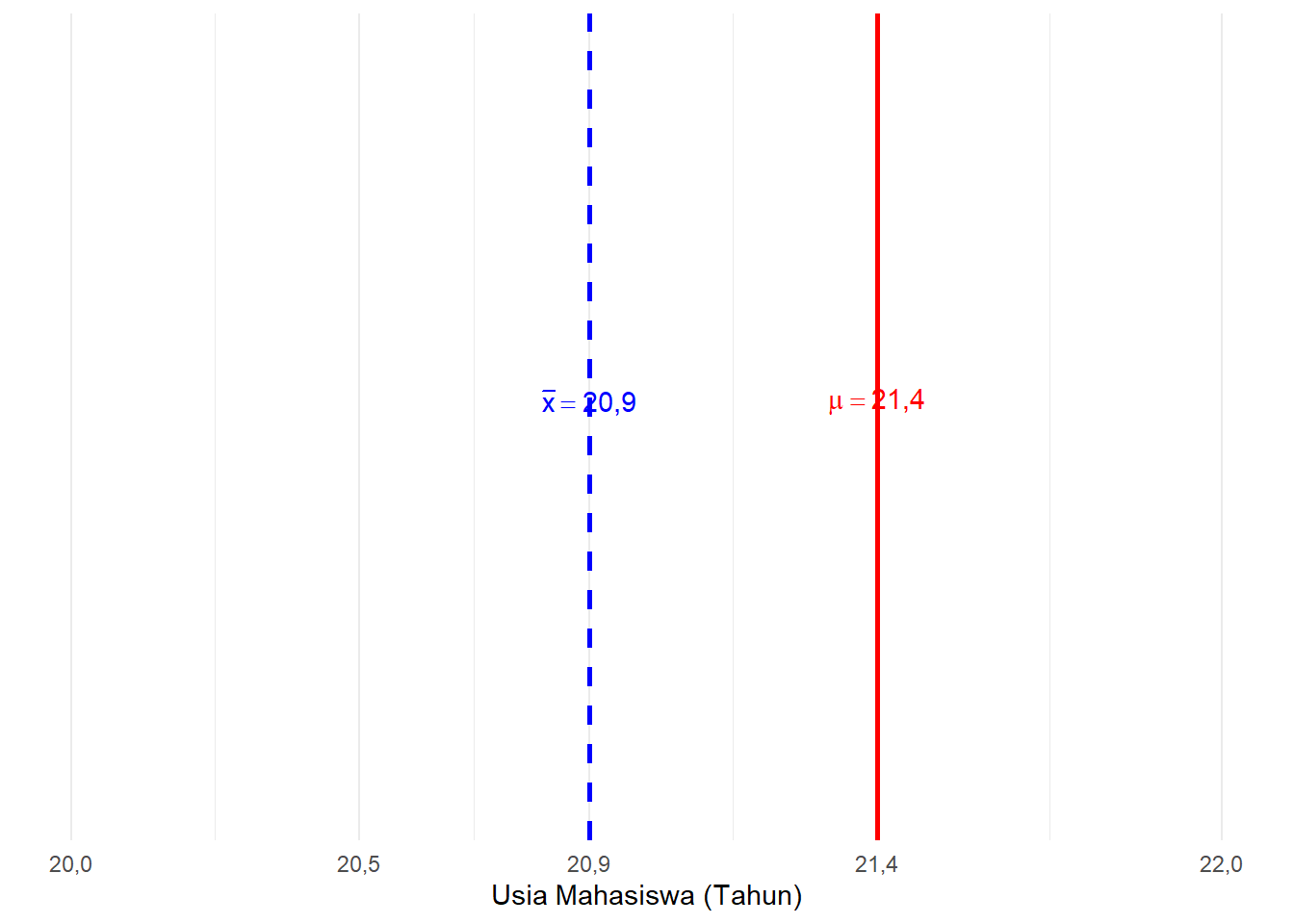
Gambar 6.1: Ilustrasi Estimasi Titik Usia Mahasiswa
Di sinilah keterbatasan estimasi titik terlihat; ia hanya menyajikan satu angka saja, sehingga sangat rentan meleset dari nilai parameter yang sebenarnya. Oleh karena itu, kita membutuhkan estimasi yang lebih “aman”, yakni estimasi berupa rentang nilai yang akan kita pelajari pada bagian selanjutnya.
6.2.2 Estimasi Rentang
Berbeda dari estimasi titik, estimasi rentang (interval estimate) menetapkan parameter populasi dalam sebuah rentang nilai. Rentang inilah yang disebut interval kepercayaan (confidence interval), yang memuat nilai parameter populasi yang sebenarnya. Dengan demikian, kita bisa menebak parameter yang sebenarnya dengan kemungkinan yang lebih besar (Kachigan 1986).
Rentang kepercayaan dibentuk dari dua nilai batas, yaitu batas bawah (lower limit) dan batas atas (upper limit). Batas bawah dan batas atas ini diperoleh dari pengurangan dan penambahan margin kesalahan (margin of error) dari estimasi titik yang kita hitung dari sampel.
Studi Kasus: Keuntungan Estimasi Rentang
Telah disebutkan bahwa rentang kepercayaan diperoleh dari pengurangan dan penambahan margin kesalahan (margin of error) atas estimasi titik yang kita hitung dari sampel.
Melanjutkan contoh usia mahasiswa, alih-alih hanya menyatakan estimasi parameter sebesar 20,90 tahun, misalkan kita memperhitungkan pula margin of error-nya sebesar \(\pm 0,60\) tahun. Hasil pengurangannya memperoleh batas bawah interval pada 20,30 tahun, dan penambahannya menghasilkan batas atas interval usia pada 21,50 tahun.
Artinya, kita memperkirakan bahwa nilai parameter rata-rata usia seluruh mahasiswa ITERA berada pada rentang antara 20,30 tahun hingga 21,50 tahun. Karena tebakan parameter sesungguhnya (\(\mu = 21,4\)) berada di dalam wilayah ini, maka tebakan kita jauh lebih akurat.
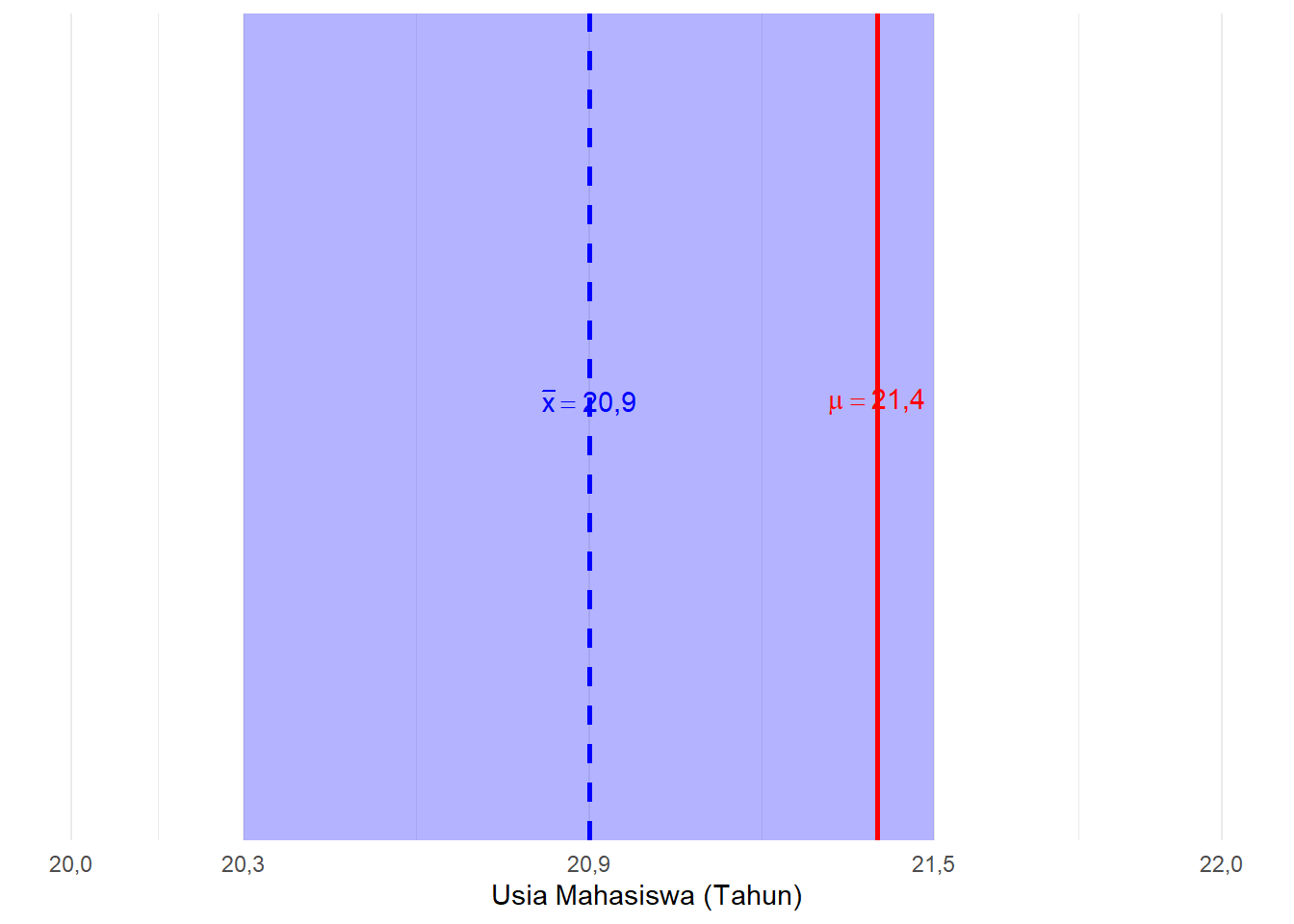
Gambar 6.2: Ilustrasi Estimasi Rentang Usia Mahasiswa
Estimasi ini jauh lebih mendekati kebenaran dibandingkan hanya menyebut estimasi titik sebesar 20,90 tahun tadi. Memperhitungkan ketidakpastian dalam proses pengambilan sampel dengan batas-batas ini membuat kita menemukan rentang parameter seperti yang diilustrasikan oleh area arsir berwarna biru pada Gambar 6.2 tersebut.
6.3 Konsep Perhitungan Rentang Kepercayaan Sebagai Estimasi Rentang
Rentang kepercayaan atau interval kepercayaan (confidence interval) adalah bentuk estimasi rentang dalam statistika inferensial yang merupakan estimasi titik (\(\bar{x}\) atau \(\hat{p}\)) yang kita kurangkan dan tambahkan dengan margin of error (MoE) (Healey 2021). Jadi, rumus dasar untuk rentang kepercayaan adalah berikut.
\[ \begin{equation} c.i. = \text{estimasi titik} \pm MoE \tag{6.1} \end{equation} \]
Sedangkan \(MoE\) sendiri sebenarnya adalah perkalian antara nilai kritis dan standard error. Dengan demikian, rumus dasar confidence interval sebenarnya adalah:
\[ MoE = Z_{\alpha/2} \times \text{S.E.} \tag{6.2} \]
Maka, dengan mensubstitusi \(MoE\) dengan persamaan (6.2), persamaan (6.1) menjadi:
\[ c.i. = \text{estimasi titik} \pm (Z_{\alpha/2} \times \text{S.E.}) \tag{6.3} \]
Nilai kritis (\(Z_{\alpha/2}\)) ini adalah nilai yang berkaitan dengan tingkat kepercayaan dan signifikansi (\(\alpha\)). Singkatnya, tingkat kepercayaan + signifikansi harus menghasilkan angka 100%. Konsepnya akan kita dalami di subbab 6.4.
Nilai kritis dicari dengan membagi 2 terlebih dahulu nilai \(\alpha\) di kiri dan kanan kurva distribusi statistik, kemudian menemukan nilai yang menjadi pembatasnya dengan tabel nilai Z seperti yang sudah kita lakukan pada 5.7.4. Gambar 6.3 berikut mengilustrasikan pencarian nilai kritis pada signifikansi sebesar 10%.
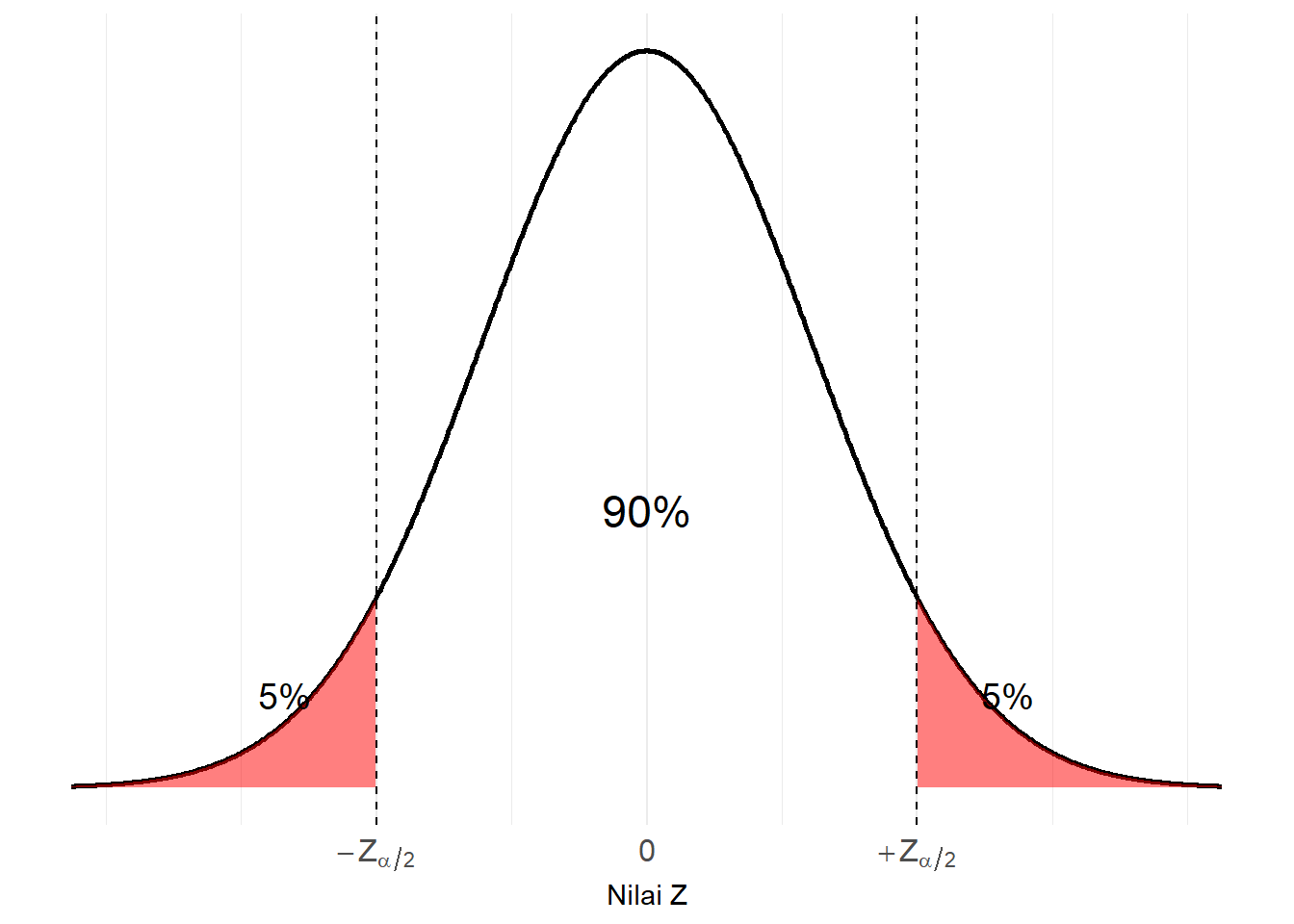
Gambar 6.3: Ilustrasi Nilai Kritis Z pada Distribusi Normal, contoh \(lpha = 10%\)
Dalam bab ini kita akan mempelajari perhitungan rentang kepercayaan untuk parameter rata-rata (\(\mu\)) dan proporsi (\(P\)).
6.3.1 Perhitungan Rentang Kepercayaan Rata-rata
Kita akan mulai dengan estimasi parameter untuk variabel numerik, yakni rata-rata. Estimasi parameter rata-rata, berarti kita memperkirakan nilai rata-rata populasi berdasarkan nilai rata-rata yang diperoleh dari sampel (Kachigan 1986).
Dari sampel ini diperoleh sebuah nilai rata-rata (\(\bar{x}\)) yang berfungsi sebagai estimasi titik. Estimasi titik ini kita tambah dan kurangkan dengan MoE agar menjadi rentang (Healey 2021).
Rumus S.E. untuk rata-rata ditunjukkan oleh Persamaan (5.3), maka, berdasarkan Persamaan (6.2), MoE untuk interval rata-rata adalah:
\[ MoE = Z_{\alpha/2} \times \frac{s}{\sqrt{n}} \tag{6.4} \]
dengan keterangan: \(s\) adalah simpangan baku sampel dan \(n\) adalah ukuran sampel. Dengan demikian, rumus lengkap untuk perhitungan rentang kepercayaan rata-rata adalah:
\[ c.i. = \bar{x} \pm Z_{\alpha/2} \frac{s}{\sqrt{n}} \tag{6.5} \]
Studi Kasus: Menghitung Rata-rata Jarak Tempat Tinggal Mahasiswa ITERA Berdasarkan Jenis Tempat Tinggalnya
Diketahui dari hasil survei terhadap 333 sampel mahasiswa ITERA, sebaran jenis tempat tinggalnya, beserta statistik jarak tempat tinggalnya, ditampilkan sebagai berikut.
| Jenis Tempat Tinggal | \(n\) | \(\bar{x}\) (km) | \(s\) (km) |
|---|---|---|---|
| Kos Bersama-sama | 26 | 4,87 | 2,82 |
| Kos Sendiri | 200 | 4,78 | 2,21 |
| Rumah Mengontrak Bersama | 107 | 4,79 | 2,13 |
Kita akan menghitung rentang kepercayaan rata-rata jarak tempat tinggal mahasiswa untuk setiap jenis tempat tinggal dengan tingkat kepercayaan 95%.
Jawaban:
Langkah-1: Menghitung Statistik
Dari Tabel 6.2 tersebut kita dapat melihat bahwa rata-rata jarak tempat tinggal mahasiswa sudah tersedia dan bervariasi menurut jenis hunian.
Langkah-2: Menentukan Nilai Kritis Z
Langkah berikutnya adalah menentukan nilai kritis \(Z_{\alpha/2}\) sesuai dengan tingkat kepercayaan yang digunakan. Nilai kritis \(Z_{\alpha/2}\) diperoleh dari distribusi normal baku.
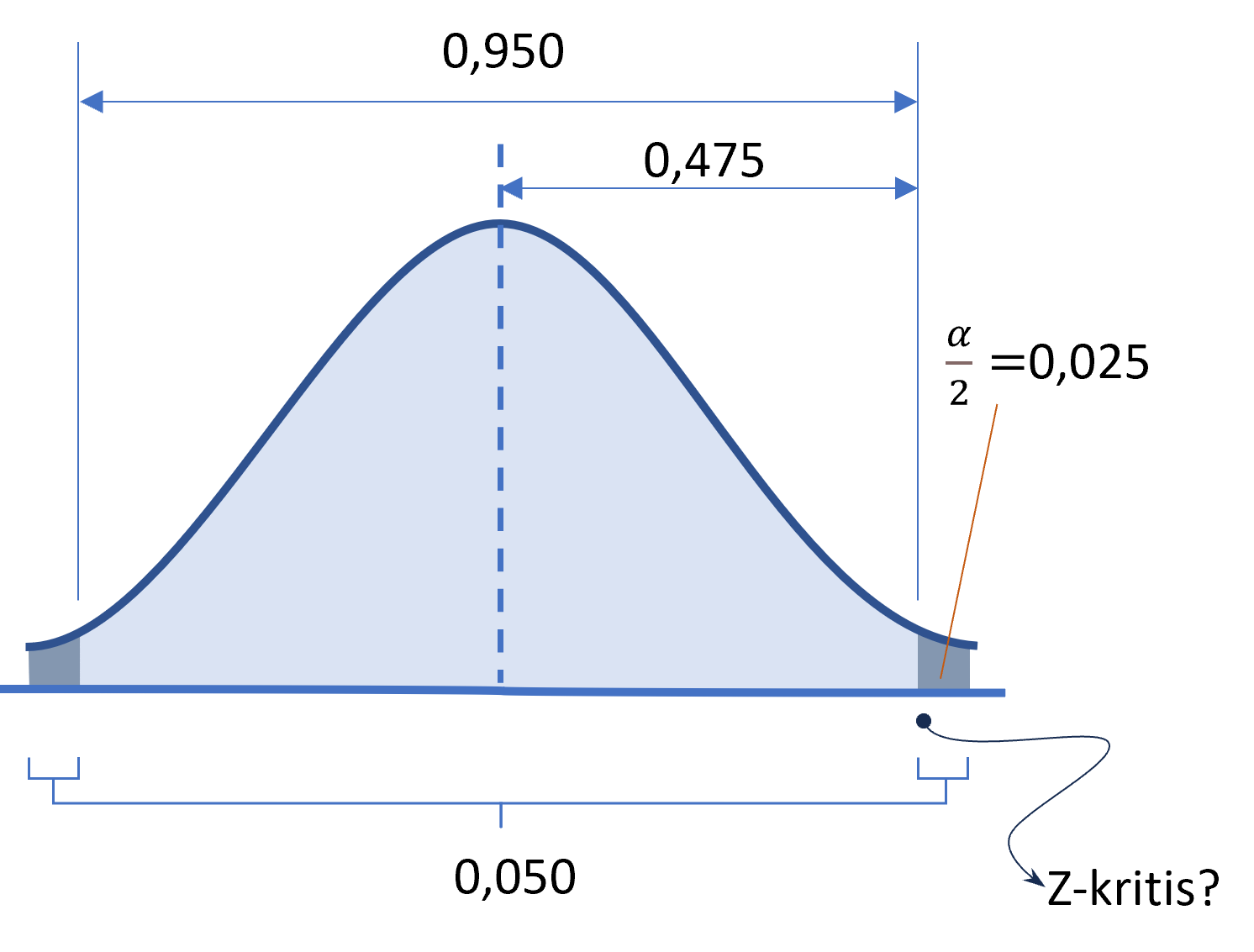
Gambar 6.4: Membagi Dua Nilai Alpha
Nilai tingkat kepercayaan yang kita gunakan adalah luas area di bawah kurva yang berwarna biru terang, yaitu 0,950. Artinya, kita menggunakan nilai \(\alpha\) sebesar 0,05 atau 5%. Nilai \(\alpha\) ini dibagi 2 (\(\alpha/2\)) dan ditempatkan di kiri dan kanan kurva normal. Dengan demikian, luas area biru terang menjadi bernilai \(0,95 / 2 = 0,475\) dari titik 0 di tengah.
Nilai Z diperoleh dari area seluas 0,475 di bawah kurva normal mulai dari titik tengah (0). Dengan mencocokkan pada tabel distribusi normal, didapatkan nilai \(Z=1,96\), yang berasal dari kombinasi angka 1,9 pada sisi vertikal dan 0,06 pada sisi horizontal tabel.
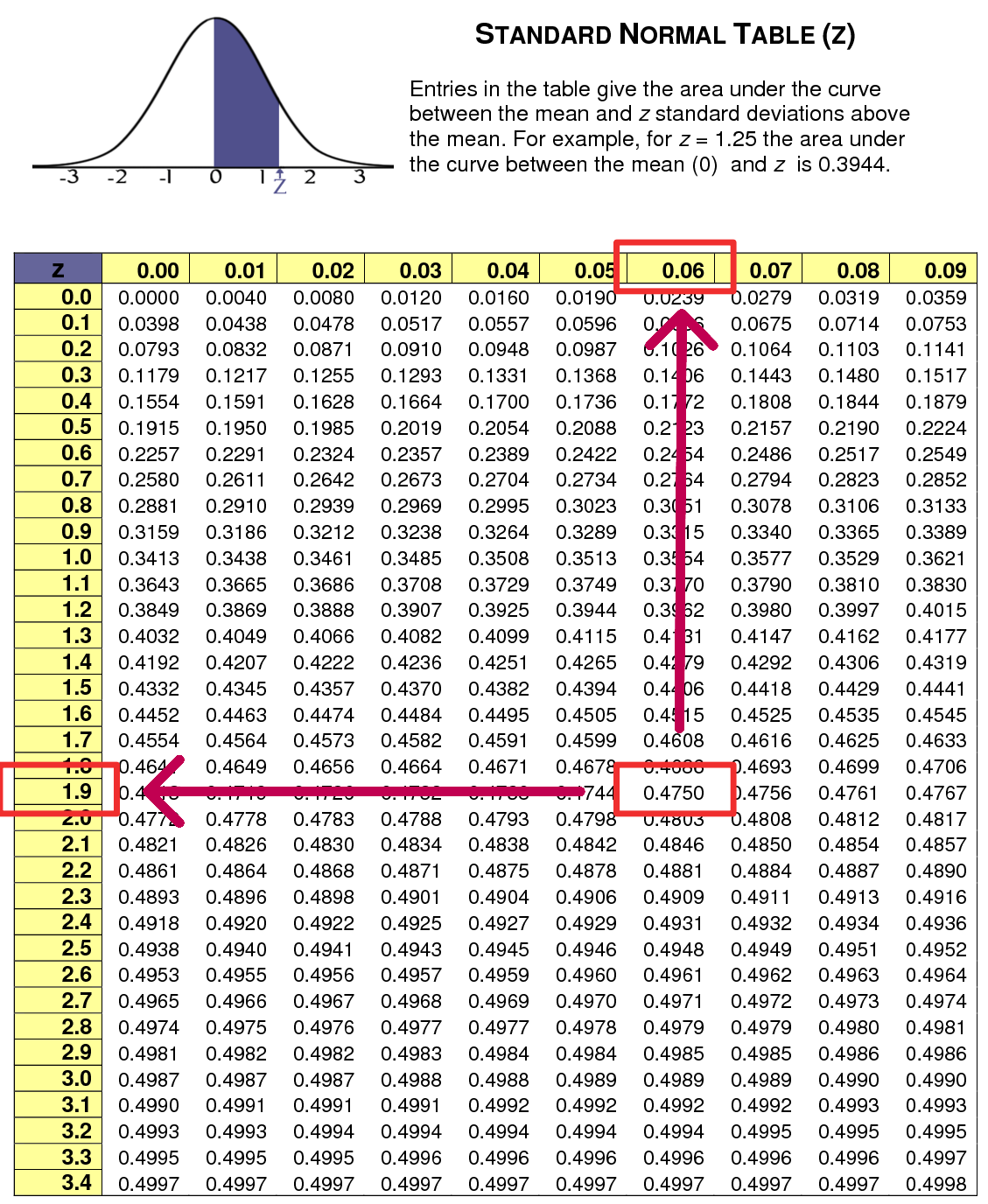
Gambar 6.5: Mencari Nilai Z
Langkah-3: Menghitung Rentang Kepercayaan dan Menarik Kesimpulan
Dengan \(Z_{\alpha/2} = 1,96\), rentang kepercayaan dihitung per kategori menggunakan simpangan baku dan jumlah objek masing-masing. Mensubstitusi nilai-nilai per kategori dari Tabel 6.2 ke dalam rumus Persamaan (6.5) menghasilkan:
Kos Sendiri (\(n = 200\), \(\bar{x} = 4,78\), \(s = 2,21\)):
\[ \begin{aligned} c.i. &= 4,78 \pm 1,96 \times \frac{2,21}{\sqrt{200}} \\ &= 4,78 \pm 0,3062 \\ &= [4,47 \text{ km};\ 5,09 \text{ km}] \end{aligned} \]
Rumah Mengontrak Bersama (\(n = 107\), \(\bar{x} = 4,79\), \(s = 2,13\)):
\[ \begin{aligned} c.i. &= 4,79 \pm 1,96 \times \frac{2,13}{\sqrt{107}} \\ &= 4,79 \pm 0,4038 \\ &= [4,39 \text{ km};\ 5,19 \text{ km}] \end{aligned} \]
Kos Bersama-sama (\(n = 25\), \(\bar{x} = 4,91\), \(s = 2,87\)):
\[ \begin{aligned} c.i. &= 4,91 \pm 1,96 \times \frac{2,87}{\sqrt{25}} \\ &= 4,91 \pm 1,1252 \\ &= [3,78 \text{ km};\ 6,04 \text{ km}] \end{aligned} \]
Catatan: Kategori Rumah Mengontrak Pribadi hanya memiliki 1 responden (\(n = 1\)), sehingga simpangan baku tidak dapat dihitung dan rentang kepercayaan tidak dapat diestimasi. Kategori ini tidak disertakan dalam perhitungan.
Dari ketiga hasil di atas, terlihat bahwa rata-rata jarak tempat tinggal ketiga jenis hunian relatif serupa, berkisar antara 4,47 km hingga 5,19 km dari kampus. Perbedaan yang paling mencolok terletak pada lebar rentang: kategori Kos Bersama-sama memiliki rentang paling lebar (\(\pm 1,13\) km) karena ukuran sampelnya jauh lebih kecil (\(n = 25\)), yang mencerminkan ketidakpastian estimasi yang lebih besar. Sebaliknya, Kos Sendiri dan Rumah Mengontrak Bersama memiliki rentang lebih sempit karena jumlah respondennya lebih besar.
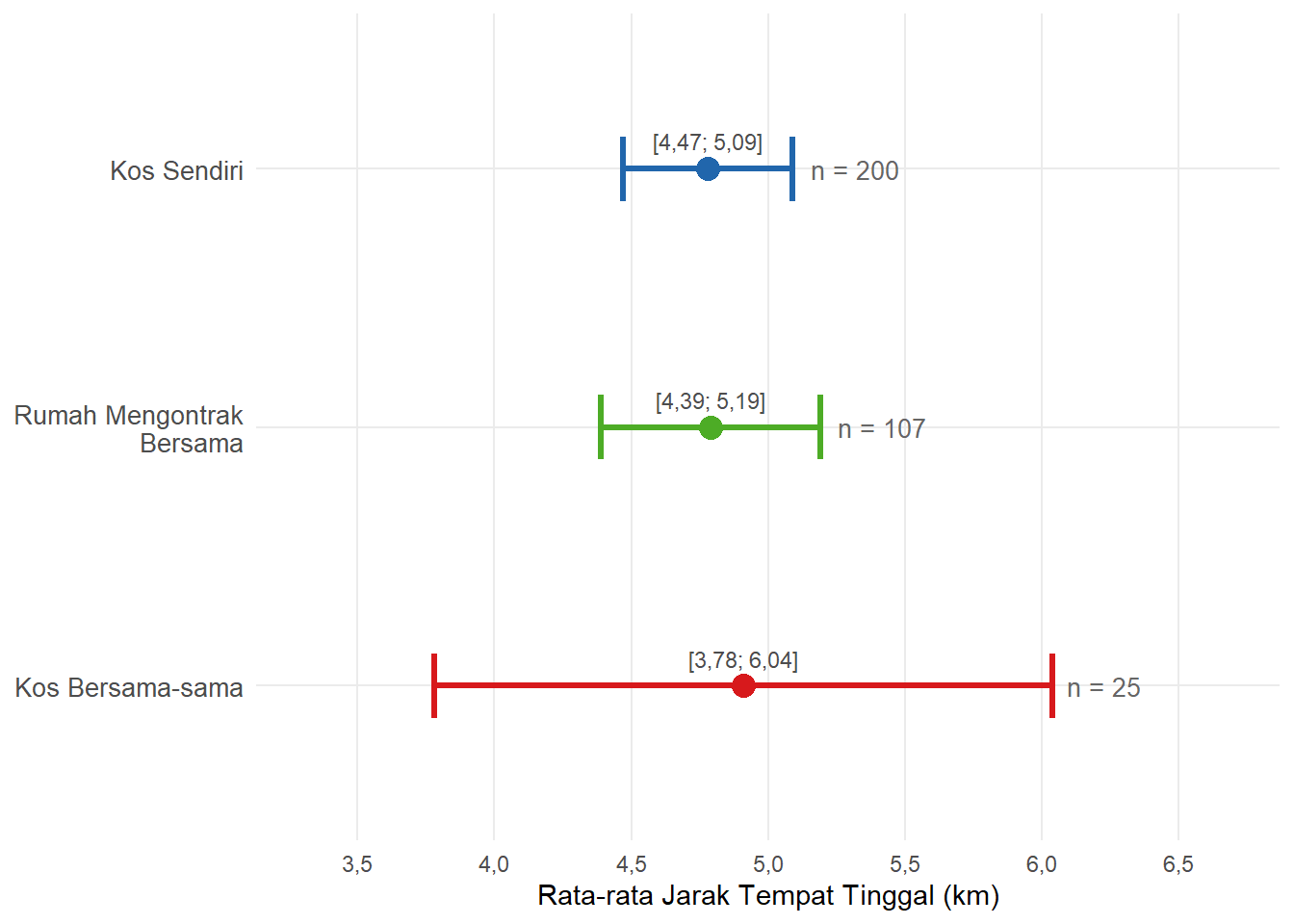
Gambar 6.6: Interval Kepercayaan 95% Rata-rata Jarak Tempat Tinggal per Jenis Hunian
Jawablah soal berikut untuk melatih keterampilan Anda menghitung rentang kepercayaan rata-rata.
Soal Evaluasi 12
Dari suatu sampel dosen ITERA berjumlah 73 orang diperoleh rata-rata usianya adalah 30 tahun dan simpangan bakunya 2,9 tahun. Anda diminta menggunakan probabilitas galat, \(\alpha = 5\%\) STP-5.1
- Berapakah tingkat kepercayaan (confidence level) yang digunakan?
- Berapakah nilai standar (Z-score) yang kita pakai?
- Hitunglah rentang kepercayaan (confidence interval) rata-rata usia seluruh dosen ITERA menggunakan data sampel kita tadi.
6.3.2 Perhitungan Rentang Kepercayaan Proporsi
Perhitungan rentang kepercayaan proporsi hanya berbeda pada rumus S.E.-nya (Kachigan 1986). S.E.untuk distribusi statistik sampel proporsi dihitung dengan rumus berikut.
\[ \text{S.E.} = \sqrt{\frac{\hat{p}(1-\hat{p})}{n}} \tag{6.6} \]
dengan keterangan: \(\hat{p}\) adalah proporsi sampel dan \(n\) ukuran sampel (Healey 2021). Maka, rumus rentang kepercayaan untuk statistik proporsi adalah:
\[ c.i. = \hat{p} \pm Z_{\alpha/2} \sqrt{\frac{\hat{p}(1-\hat{p})}{n}} \tag{6.7} \]
Studi Kasus: Proporsi Mahasiswa Berdasarkan Jenis Tempat Tinggal
Masih berdasarkan data dari kasus sebelumnya, kita akang menghitung parameter proporsi mahasiswa yang tinggal berdasarkan jenis tempat tinggal, akan tetapi, kita menurunkan tingkat kepercayaan kita menjadi 91%.
Jawaban:
Langkah-1: Menghitung Statistik
Langkah awal dalam estimasi parameter proporsi adalah menghitung proporsi sampel berdasarkan data hasil survei. Proporsi sampel (\(\hat{p}\)) dihitung dengan:
\[\hat{p} = \frac{x}{n}\]
dengan:
- \(x\) = jumlah responden yang memiliki karakteristik tertentu,
- \(n\) = jumlah seluruh responden.
Berdasarkan Tabel 6.2, kita dapat menghitung proporsi tiap-tiap kategori jenis tempat tinggal. Hasilnya ditunjukkan oleh Tabel 6.3 berikut.
| Jenis Tempat Tinggal | \(n\) | \(\hat{p}\) |
|---|---|---|
| Kos Bersama-sama | 26 | 0,078 |
| Kos Sendiri | 200 | 0,601 |
| Rumah Mengontrak Bersama | 107 | 0,321 |
Langkah-2: Menentukan Nilai Kritis Z
Sama konsepnya seperti kasus sebelumnya, sebelumnya kita akan menghitung terlebih dahulu nilai \(\alpha\). Karena tingkat kepercayaan kita 91%, maka \(\alpha=9\%\) atau \(0,09\). Gambar 6.7 berikut menunjukkan area yang kita cari nilai \(Z_{\alpha/2}\)-nya, yakni \(0,405\).
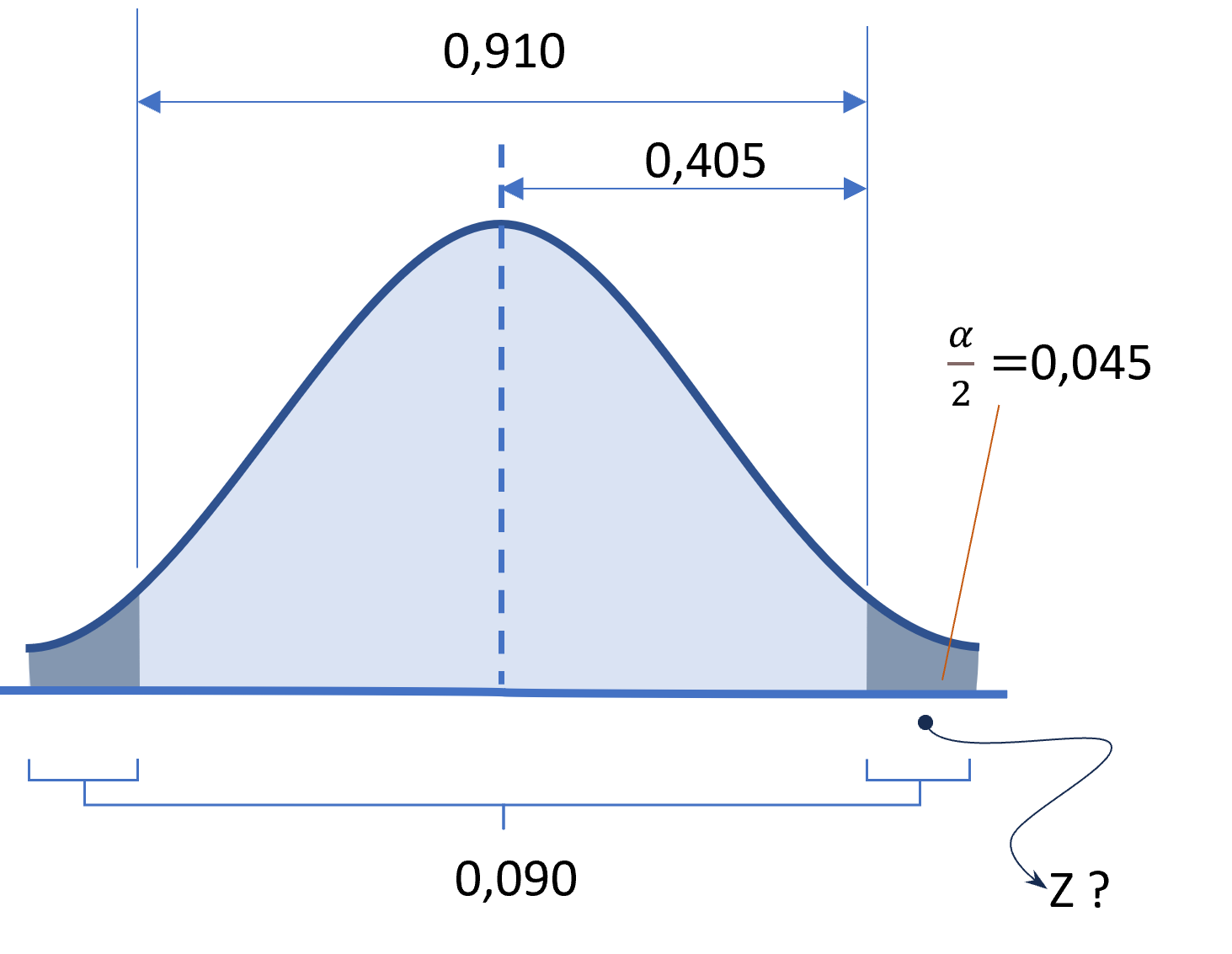
Gambar 6.7: Membagi Dua Nilai Alpha
Dari tabel nilai Z di Gambar 5.18, kita dapat memperoleh nilai Z untuk tingkat kepercayaan 91% sebagai berikut.

Gambar 6.8: Mencari Nilai Z
Langkah-3: Menghitung Rentang Kepercayaan dan Menarik Kesimpulan
Setelah seluruh komponen perhitungan ditentukan, langkah terakhir adalah menghitung rentang kepercayaan proporsi untuk setiap kategori. Nilai kritis yang digunakan adalah \(Z_{\alpha/2} = 1,31\) dan \(n = 333\). Nilai-nilai \(\hat{p}\) dari Tabel 6.3 disubstitusikan ke dalam rumus Persamaan (6.7) untuk masing-masing kategori.
Kos Sendiri (\(\hat{p} = 0,601\)):
\[ \begin{aligned} c.i. &= 0,601 \pm 1,31 \times \sqrt{\frac{0,601(1 - 0,601)}{333}} \\ &= 0,601 \pm 0,0351 \\ &= [56,59\%;\ 63,61\%] \end{aligned} \]
Rumah Mengontrak Bersama (\(\hat{p} = 0,321\)):
\[ \begin{aligned} c.i. &= 0,321 \pm 1,31 \times \sqrt{\frac{0,321(1 - 0,321)}{333}} \\ &= 0,321 \pm 0,0335 \\ &= [28,75\%;\ 35,45\%] \end{aligned} \]
Kos Bersama-sama (\(\hat{p} = 0,075\)):
\[ \begin{aligned} c.i. &= 0,075 \pm 1,31 \times \sqrt{\frac{0,075(1 - 0,075)}{333}} \\ &= 0,075 \pm 0,0189 \\ &= [5,61\%;\ 9,39\%] \end{aligned} \]
Catatan: Kategori Rumah Mengontrak Pribadi (\(n = 1\)) tidak disertakan karena tidak representatif.
Dari ketiga hasil di atas, terlihat bahwa Kos Sendiri mendominasi dengan estimasi proporsi antara 56,59% hingga 63,61% dari seluruh mahasiswa yang menyewa hunian. Rumah Mengontrak Bersama berada di posisi kedua (28,75%–35,45%), disusul Kos Bersama-sama (5,61%–9,39%). Temuan ini menunjukkan bahwa mayoritas mahasiswa ITERA memilih hunian sewa mandiri.
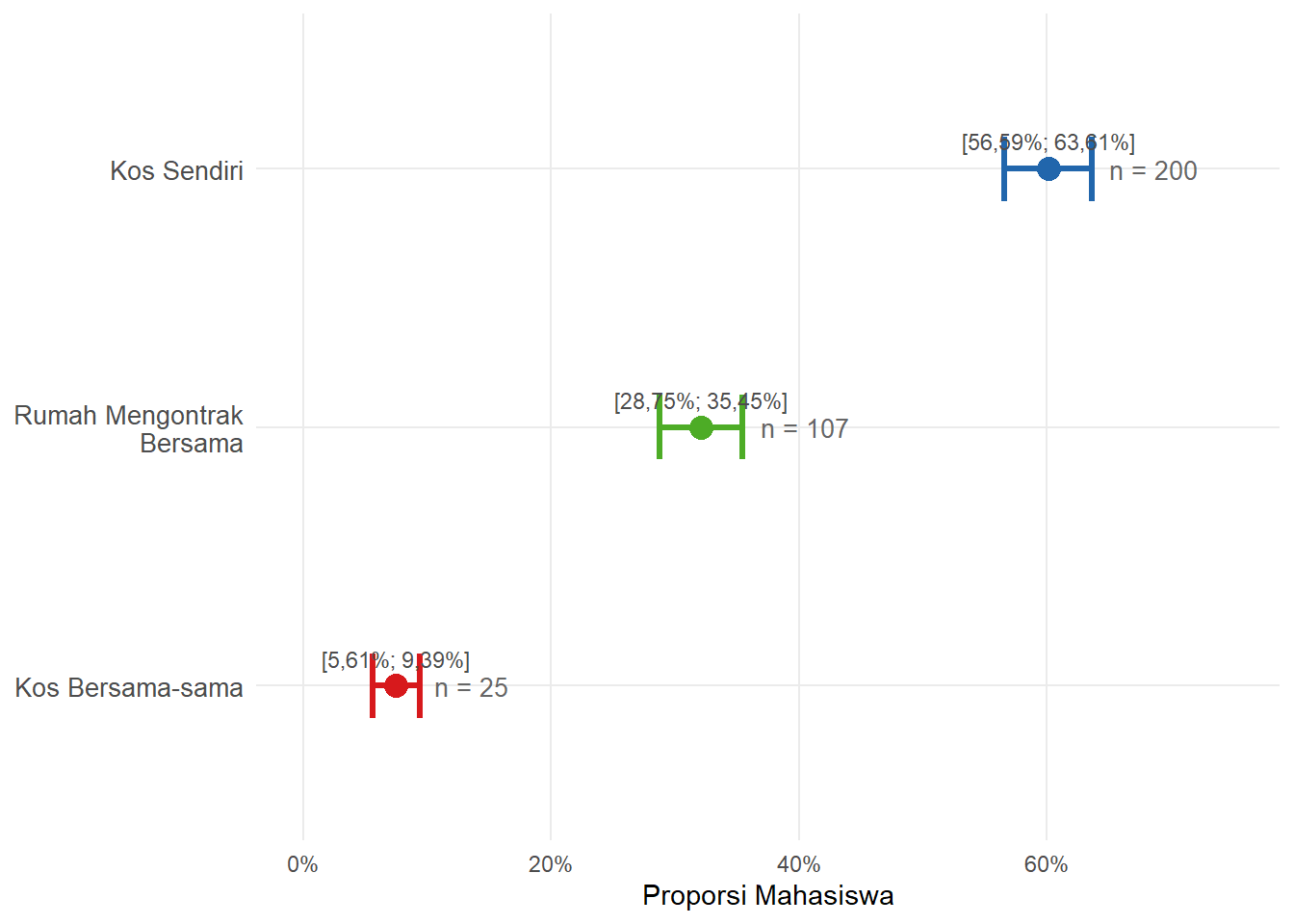
Gambar 6.9: Interval Kepercayaan 91% Proporsi Mahasiswa per Jenis Hunian
Jawablah soal berikut untuk melatih keterampilan Anda menghitung rentang kepercayaan proporsi.
Soal Evaluasi 13
Diketahui bahwa proporsi pengguna mobil pribadi dari suatu sampel mahasiswa berjumlah 429 orang adalah 0,04. STP-5.1
- Apabila kita menggunakan confidence level 93%, berapakah tingkat signifikansi kita?
- Berapakah Z-score yang kita pakai?
- Hitunglah confidence interval proporsi pengguna mobil pribadi pada populasi mahasiswa tersebut.
6.4 Lebih Dalam tentang Tingkat Kepercayaan (Confidence Level)
Kita sudah mengetahui bahwa tingkat kepercayaan penting dalam perhitungan rentang kepercayaan. Di bagian ini, kita akan menganalisis lebih dalam apa yang dinyatakan oleh angka tingkat kepercayaan dan pengaruhnya terhadap perhitungan rentang kepercayaan.
Sebelum lebih lanjut, kita harus sadar bahwa tingkat kepercayaan (confidence level, CL) berbeda dengan rentang kepercayaan (confidence interval). Jika rentang kepercayaan adalah hasil berupa interval nilai yang memperkirakan posisi parameter populasi, maka tingkat kepercayaan adalah ukuran seberapa yakin kita terhadap interval tersebut (Chase and Bown 2000).
Apa yang kita yakini? Yang kita yakini adalah dimuatnya nilai parameter dalam interval yang kita hasilkan. Keyakinan ini dinyatakan dalam bentuk probabilitas yang merupakan angka persentase atau proporsi. Misalnya pada kasus rata-rata jarak tempat tinggal mahasiswa yang mengekos sendiri. Tingkat kepercayaan 95% (0,95) bermakna dari 100 sampel yang mungkin diambil, sebanyak 95% sampel akan memuat nilai parameter. Dalam kasus ini, maka kita yakin bahwa 95% sampel yang kita ambil, yang menghasilkan rentang 4,47 km hingga 5,09 km, mencakup nilai parameter sebenarnya.
Banyak orang salah dalam menginterpretasikan angka tingkat kepercayaan. Simak pembahasan berikut untuk memahaminya.
Catatan: Salah Kaprah Tingkat Kepercayaan
Tingkat kepercayaan sering disalahmaknai sebagai peluang parameter ada di dalam interval. Jadi, nilai tingkat kepercayaan 90% bukan berarti kita 90% yakin bahwa nilai parameter ada dalam rentang kepercayaan kita. Nilai parameter populasi itu tetap, misalnya rata-rata tinggi badan seluruh mahasiswa memang punya satu angka pasti, hanya saja kita tidak tahu berapa nilainya. Oleh karena itu, kita mengambil sampel yang representatif dan menghitung statistiknya untuk mengestimasi parameter.
Dengan tingkat kepercayaan 90%, artinya kita mengatakan bahwa sampel kita tersebut hanya akan salah sebanyak 10 kali pengambilan saja dari 100 kali pengambilan yang mungkin. Dengan kata lain, 90 sampel tersebut akan benar-benar berisi nilai parameter populasi yang sebenarnya.
Satu lagi besaran yang berpengaruh terhadap perhitungan rentang kepercayaan dalam statistika inferensial adalah tingkat kesalahan atau signifikansi. Dalam literatur statistika berbahasa Inggris, istilah ini disebut juga error term atau significance level, atau significance saja (Chase and Bown 2000). Karena dalam statistika proses estimasi selalu melibatkan sampel yang pengambilannya tidak pernah pasti, pasti akan terdapat peluang kesalahan. Peluang kesalahan inilah yang menjadi pengertian dari tingkat kesalahan atau signifikansi tersebut. Peluang kesalahan dilambangkan dengan \(\alpha\) (/alfa/).
Dengan demikian, secara matematis, tingkat kepercayaan dituliskan sebagai \(1-\alpha\). Apabila \(\alpha = 0,05\), maka tingkat kepercayaan adalah \(1-0,05 = 0,95\) atau 95%. Ini artinya, kita dapat mengatakan bahwa 95% dari 100 kali sampel yang diambil akan menghasilkan interval yang mencakup nilai parameter, sedangkan 5% sisanya tidak.
Adapun nilai \(\alpha\) yang umum digunakan dalam penelitian adalah 0,10 (10%), 0,05 (5%), dan 0,01 (1%), tergantung seberapa besar tingkat keyakinan yang dikehendaki peneliti.
Bagaimana kaitan antara tingkat kepercayaan dengan rentang kepercayaan yang dihasilkan? Simak kasus berikut untuk memahaminya.
Studi Kasus: Pengaruh Tingkat Kepercayaan terhadap Lebar Rentang Kepercayaan
Perbedaan tingkat kepercayaan memengaruhi lebar interval estimasi. Gambar 6.10 menunjukkan hasil estimasi parameter tinggi badan mahasiswa yang nilai statistiknya adalah 165 cm, simpangan baku 3 cm, dan ukuran sampel 200 orang.
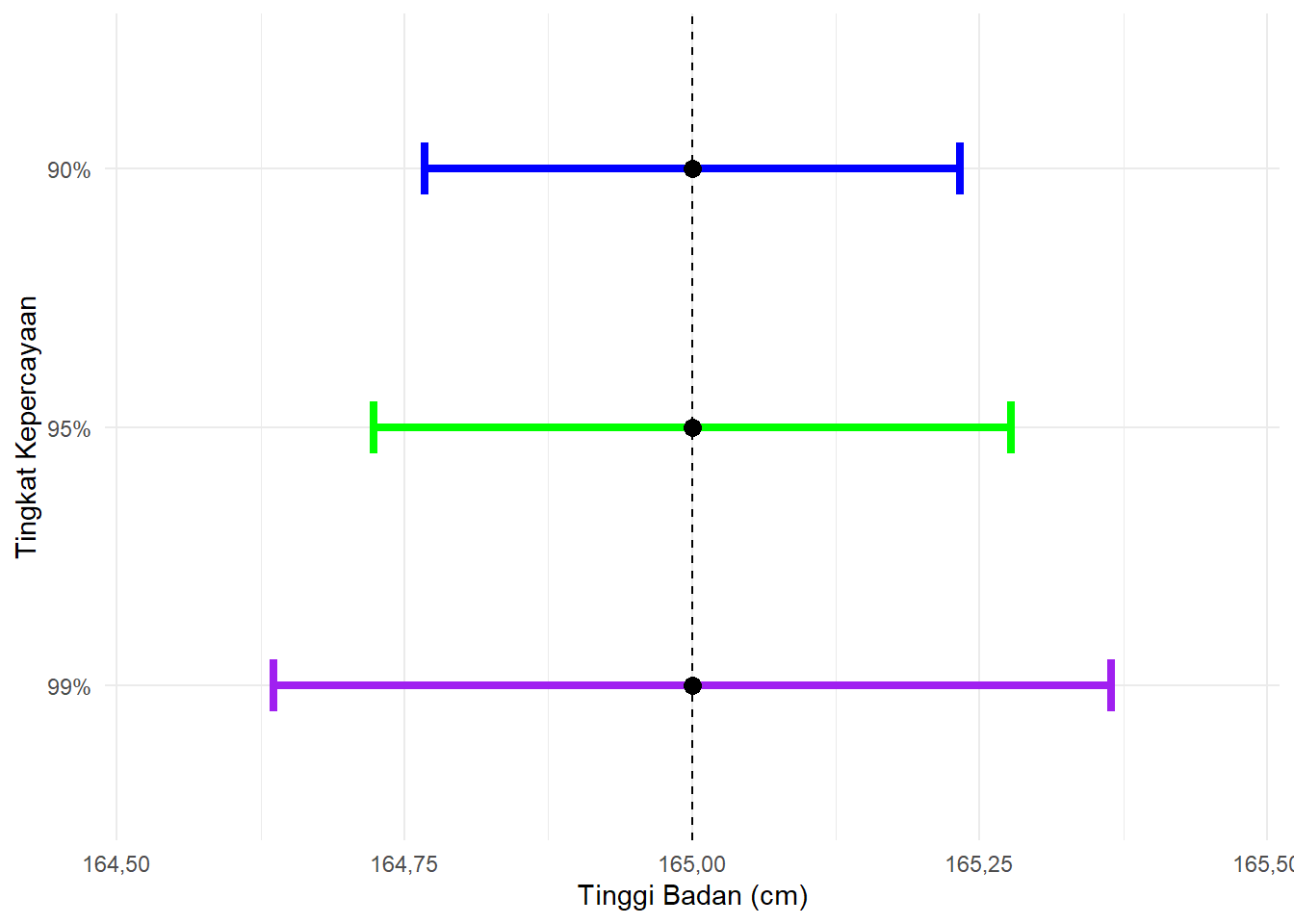
Gambar 6.10: Ilustrasi Pengaruh Nilai Tingkat Kepercayaan Terhadap Ukuran Rentang
Garis hitam putus-putus pada posisi 165 menggambarkan estimasi titik, yaitu satu nilai hasil dari sampel (Chase and Bown 2000). Garis horisontal biru, hijau, dan ungu menggambarkan interval kepercayaan dengan tingkat kepercayaan yang berbeda. Pada tingkat kepercayaan 90% (biru), intervalnya sempit, yakni 164,65-165,35 cm. Pada tingkat kepercayaan 95% (hijau), intervalnya sedikit lebih lebar, yaitu 164,58-165,42 cm. Sementara pada tingkat kepercayaan 99% (ungu), interval semakin melebar menjadi 164,45-165,55 cm. Dari sini terlihat bahwa semakin tinggi tingkat kepercayaan, semakin lebar rentang yang dihasilkan.
Interpretasi: menaikkan tingkat kepercayaan artinya memperbesar cakupan area probabilitas pada kurva distribusi statistik (ingat aturan empiris pada Gambar 5.11). Cakupan area probabilitas yang semakin besar berarti menambah cakupan nilai Z di distribusi tersebut.
Karena nilai Z mencerminkan nilai statistik yang salah satunya adalah parameter yang kita perkirakan, tingkat kepercayaan yang lebih besar memperlebar rentang perkiraan kita sehingga nilai parameter dapat tercakup dan “tertangkap” di dalam rentang perkiraan kita.
6.5 Kesimpulan: Interpretasi Estimasi Parameter
Interpretasi estimasi parameter berfokus pada pemahaman hasil berupa rentang kepercayaan atau confidence interval (Healey 2021). Rentang ini menunjukkan nilai-nilai yang mungkin menjadi parameter populasi, berdasarkan data sampel yang diperoleh. Rentang kepercayaan tidak memberikan jawaban pasti mengenai nilai parameter, melainkan memberikan batas bawah dan batas atas yang menjadi perkiraan parameter tersebut dengan tingkat keyakinan tertentu.
Lebar rentang estimasi dapat menjadi indikator kualitas estimasi. Rentang yang sempit menandakan estimasi yang lebih presisi, yang biasanya terjadi karena ukuran sampel cukup besar atau error yang relatif kecil. Sebaliknya, rentang yang lebar menunjukkan tingkat ketidakpastian yang lebih besar, sering kali disebabkan oleh ukuran sampel yang terlalu kecil atau variasi data yang tinggi. Sehingga, pemilihan jumlah sampel dan pengendalian error sangat memengaruhi kualitas estimasi.
Konsep tingkat kepercayaan membantu menjelaskan ketidakpastian dalam estimasi. Misalnya, pada tingkat kepercayaan 95% berarti ada kemungkinan 95 dari 100 sampel yang diambil akan menghasilkan interval yang mencakup parameter populasi sebenarnya. Sebaliknya, 5 dari 100 sampel (atau 5%) akan menghasilkan interval yang tidak mencakup parameter tersebut. Jika hasil sampel berbeda dari dugaan populasi, maka perbedaan itu dapat dijelaskan sebagai bagian dari kemungkinan error yang sudah diperhitungkan dalam tingkat kepercayaan.
Pada akhirnya, hasil estimasi parameter bukanlah angka yang mutlak, melainkan perkiraan yang disertai dengan tingkat kepastian tertentu. Interval kepercayaan memberikan ruang toleransi bagi ketidakpastian yang muncul dari proses pengambilan sampel, sekaligus menjadi alat bantu dalam pengambilan keputusan berbasis data.