Modul 9 Analisis Hubungan Kausalitas: Regresi Linear Sederhana dan Berganda
Setelah mempelajari modul ini, Anda diharapkan dapat:
- mampu menghasilkan regresi linear sederhana dengan perangkat lunak komputer STP-13.3
- mampu menghasilkan persamaan regresi linear berganda dengan perangkat lunak komputer STP-14.3
9.1 Pendahuluan
Analisis regresi linear adalah analisis statistik untuk menyatakan hubungan sebab-akibat (kausalitas) antar minimal dua variabel. Analisis regresi linear yang melibatkan dua variabel saja (satu variabel dependen dan satu variabel independen), kita sebut sebagai regresi linear sederhana, sedangkan analisis regresi linar yang melibatkan lebih dari dua variabel (satu variabel dependen dan lebih dari satu variabel independen) kita sebut sebagai regresi linear berganda (multiple linear regression)
Analisis regresi linear mewajibkan tingkat pengukuran minimal untuk variabel dependennya adalah metrik. Sementara itu, variabel independennya dapat berupa metrik atau bukan (ordinal/nominal).
Analisis regresi linear menghasilkan persamaan yang disebut persamaan regresi linear. Bentuk umum persamaan regresi linear tersebut adalah sebagai berikut.
\[ y = \beta_0 + \beta_1x \]
dengan
- \(y\) adalah variabel dependen (disebut juga variabel respons atau predicted variable)
- \(x\) adalah variabel independen (disebut juga variabel explanatory atau predictor variable)
- \(\beta_0\) adalah konstanta yang menjadi intercept, yaitu nilai \(y\) ketika \(x=0\)
- \(\beta_1\) adalah koefisien yang menyatakan seberapa besar perubahan \(y\) ketika satu unit nilai \(x\) berubah.
Persamaan regresi linear di atas adalah untuk analisis regresi linear sederhana, yakni analisis regresi linear yang melibatkan dua variabel saja. Untuk regresi linear berganda, kita hanya perlu menambahkan pasangan \(\beta\) dan \(x\) lainnya, sehingga bentuk umum untuk persamaan regresi linear berganda adalah seperti berikut.
\[ y = \beta_0 + \beta_1x_1 + \beta_2x_2 + ... + \beta_kx_k \]
dengan
- \(x_k\) adalah variabel independen ke-\(k\)
- \(\beta_k\) adalah koefisien untuk variabel independen ke-\(k\) tersebut
9.2 Penjelasan Kasus
Dalam praktikum kali ini, kita akan memodelkan hubungan kausal antara dua variabel metrik: jarak tempat tinggal ke kampus dan biaya perjalanan sepekan untuk mahasiswa-mahasiswi yang menggunakan kendaraan layanan online saja. Harga perjalanan menggunakan layanan online tentunya dipengaruhi oleh jarak tempuh kendaraan tersebut. Hubungan kausal ini menjadi kasus untuk regresi linear sederhana.
Untuk regresi linear berganda, kita akan melibatkan satu variabel tambahan sebagai variabel independen, yakni variabel berjenis kategoris, sehingga kita memiliki total variabel sejumlah 3 buah (1 variabel dependen, 2 variabel independen).
9.3 Memuat Pustaka (Libraries) yang Diperlukan
Seperti biasa, kita perlu memuat pustaka (libraries) yang diperlukan dalam pengolahan data kita. Seperti halnya juga analisis korelasi variabel metrik, kita tidak lagi menggunakan tabel silang, tetapi kita langsung menganalisis kolom-kolom yang ada di dataset kita.
Pastikan juga kalian mengunduh dan menginstal pustaka broom.helpers yang akan kita gunakan untuk menampilkan summary model.
install.packages("broom.helpers")9.4 Memuat Dataset
Kita akan menggunakan dataset keempat kampus di Kota Bandar Lampung dan sekitarnya sebagai bahan. Kemudian kita akan menyaring objek-objek yang memiliki nilai variabel kendaraan utama sama dengan 'Layanan online'.
# Membaca data dari file csv
data_mahasiswa <- read_csv2("datasets/Data Praktikum 08.csv")
# Memisahkan data mahasiswa yang menggunakan kendaraan online sebagai moda utama
data_mahasiswa_online <- data_mahasiswa |>
filter(`kendaraan utama` == "Layanan online")Mari biasakan untuk melihat datanya, seperti jumlah objek dan nama-nama variabelnya dengan perintah glimpse().
glimpse(data_mahasiswa_online)
## Rows: 188
## Columns: 22
## $ Kampus_PT <chr> "ITERA", "ITERA", "ITERA", "ITERA", "ITERA",…
## $ `Nomor urut` <dbl> 80, 31, 107, 339, 349, 28, 286, 421, 219, 27…
## $ `Jenis Kelamin` <chr> "Perempuan", "Perempuan", "Laki-laki", "Laki…
## $ Umur <dbl> 23, 22, 21, 18, 20, 21, 19, 19, 19, 21, 21, …
## $ Fakultas <chr> "FTIK", "FS", "FTI", "FTI", "FTI", "FTIK", "…
## $ Prodi <chr> "Perencanaan Wilayah dan Kota", "Farmasi", "…
## $ `Tingkat Semester` <chr> "Semester 7-8", "Semester 7-8", "Semester 7-…
## $ `Uang Saku` <chr> "1 - 2 Jt", "< 1 Jt", "1 - 2 Jt", "1 - 2 Jt"…
## $ `jumlah mobil` <dbl> 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
## $ `jumlah motor` <dbl> 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
## $ `jumlah sepeda` <dbl> 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
## $ `kendaraan utama` <chr> "Layanan online", "Layanan online", "Layanan…
## $ `jenis tempat tinggal` <chr> "Rumah pribadi", "Rumah mengontrak bersama",…
## $ jarak <dbl> 5.23, 3.56, 3.70, 6.33, 2.05, 5.03, 5.57, 8.…
## $ `biaya sepekan` <dbl> 144, 100, 100, 100, 90, 80, 80, 80, 70, 70, …
## $ `Jumlah Perjalanan Senin` <dbl> 2, 2, 2, 0, 4, 2, 3, 2, 2, 2, 2, 4, 2, 2, 4,…
## $ `Jumlah Perjalanan Selasa` <dbl> 2, 2, 1, 4, 2, 2, 2, 2, 2, 2, 2, 2, 4, 2, 4,…
## $ `Jumlah Perjalanan Rabu` <dbl> 2, 2, 3, 4, 4, 2, 4, 2, 3, 2, 0, 2, 2, 2, 4,…
## $ `Jumlah Perjalanan Kamis` <dbl> 2, 2, 0, 2, 4, 2, 4, 2, 4, 2, 2, 2, 2, 0, 4,…
## $ `Jumlah Perjalanan Jumat` <dbl> 2, 4, 1, 5, 2, 2, 2, 2, 2, 2, 2, 2, 2, 0, 0,…
## $ `Jumlah Perjalanan Sabtu` <dbl> 2, 0, 1, 0, 2, 2, 0, 0, 2, 1, 0, 2, 2, 0, 2,…
## $ `Jumlah Perjalanan Ahad` <dbl> 2, 2, 0, 2, 2, 3, 2, 0, 0, 0, 3, 0, 0, 2, 2,…9.5 Pola Hubungan Data
Sebagai pendahuluan, kita akan mengidentifikasi kekuatan, arah, dan pola hubungan antara variabel dependen dan independen kita (biaya perjalanan sepekan dan jarak tempat tinggal-kampus). Untuk itu kita dapat menghitung koefisien korelasi untuk hubungan variabel metrik juga, yakni koefisien korelasi Pearson’s \(r\).
Pola hubungan akan kita analisis dengan membuat diagram pencar (scatter plot) antara variabel dependen dengan variabel independennya.
9.5.1 Menghitung Koefisien Pearson’s \(r\)
Menghitung koefisien korelasi Pearson’s \(r\) dapat kita lakukan dengan perintah cor() dengan atribut method = "pearson" setelah terlebih dahulu menyimpan nilai masing-masing variabel ke dalam suatu vektor.
# Menyimpan vektor jarak dan biaya (perjalanan) sepekan ke dalam variabel
# 'x' dan 'y'
x <- data_mahasiswa_online$jarak
y <- data_mahasiswa_online$`biaya sepekan`
cor(x, y, use = "complete.obs", method = "pearson")Aktivitas Mandiri 1
Tuliskan interpretasi kalian terhadap koefisien korelasi antara variabel jarak tempuh dengan biaya perjalanan sepekan tersebut.
Petunjuk: ulas kekuatan serta arah hubungannya serta maknai secara kontekstual ulasan tersebut
9.5.2 Membuat Diagram Pencar
Membuat diagram pencar dapat dilakukan dengan menerapkan perintah geom_point() dari pustaka ggplot2 yang dimuat bersama pustaka tidyverse.
# Membuat diagram pencar antara variabel jarak dan biaya transportasi sepekan
# untuk mahasiswa yang pakai layanan online
scp <- ggplot(
data = data_mahasiswa_online,
mapping = aes(
x = jarak, # variabel di sumbu X
y = `biaya sepekan`
)
) + # variabel di sumbu Y
geom_point(
color = "navy", # perintah untuk menampilkan diagram pencar dengan warna biru
alpha = 0.2, # mengatur transparansi titik
size = 1.5, # mengatur ukuran titik
shape = 15
) + # mengatur bentuk titik menjadi persegi
labs(
title = "Jarak tempat tinggal vs. Biaya Transportasi Sepekan",
subtitle = "Mahasiswa dengan Moda Transportasi Layanan Online",
y = "Biaya transportasi sepekan (ribu rupiah)",
x = "Jarak dari tempat tinggal ke kampus (km)"
)
# Menampilkan diagram
scp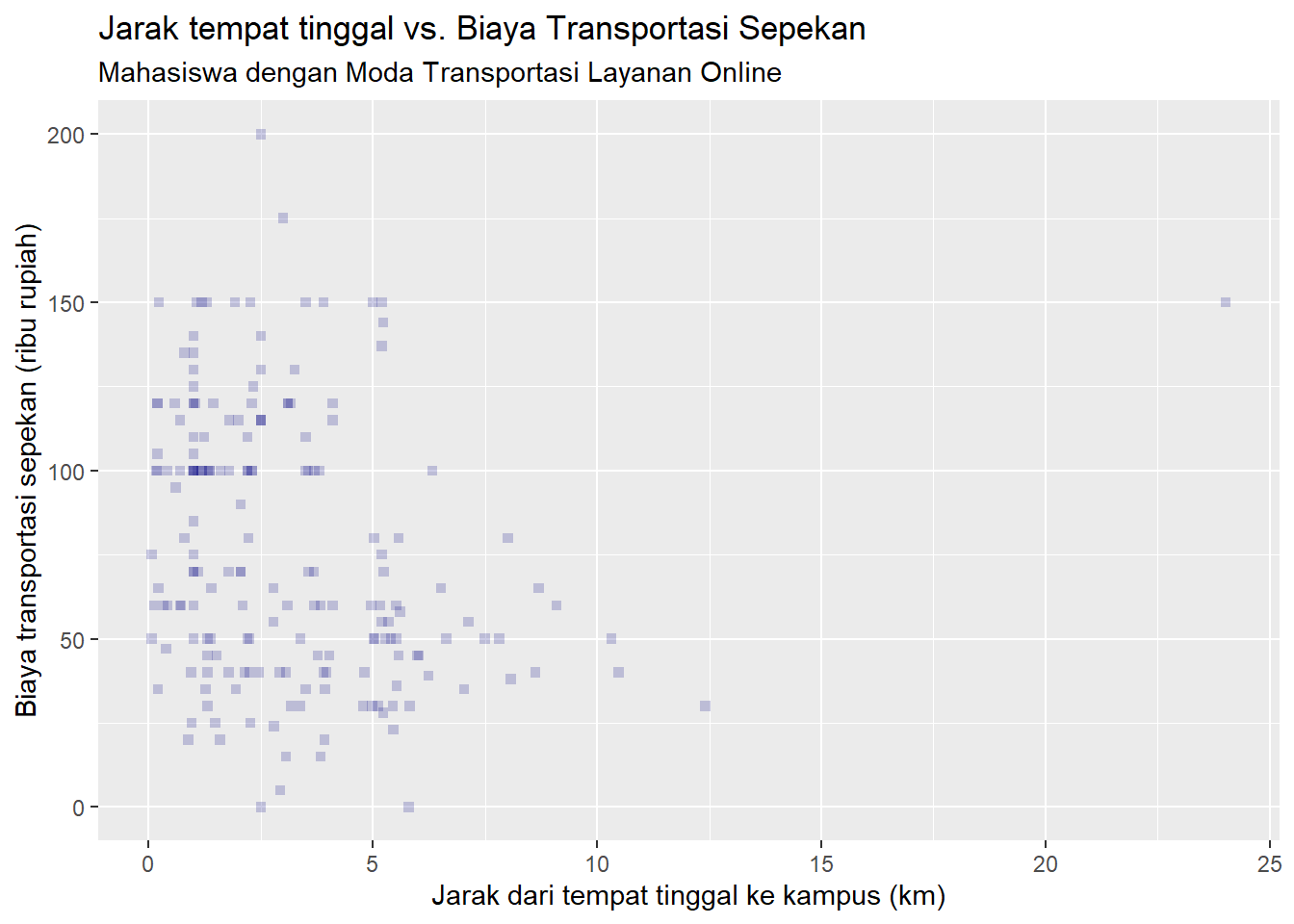
Setelah Anda melakukan pembuatan diagram pencar tersebut, Anda akan menyadari bahwa kita memiliki outlier (pencilan), yakni objek yang memiliki nilai jarak dari tempat tinggal ke kampus mencapai hampir 25 km.
Keberadaan pencilan ini akan mengganggu hasil analisis kita. Mari kita buktikan dengan menghilangkan data pencilan tersebut.
# Menghilangkan observasi pencilan dengan menyaring observasi dengan
# jarak < 15 km
data_mahasiswa_online <- data_mahasiswa_online |>
filter(jarak < 15)Di sini kita akan menghitung ulang nilai koefisien korelasi kita.
# Menghitung korelasi antara biaya sepekan dengan jarak dari dataset yang
# sudah dihilangkan pencilannya
x <- data_mahasiswa_online$jarak
y <- data_mahasiswa_online$`biaya sepekan`
cor(x, y, method = "pearson")Aktivitas Mandiri 2
Tuliskan interpretasi kalian terhadap perbedaan nilai koefisien \(r\) sebelum dan setelah pencilan dihilangkan.
Kita pun dapat memeriksa hasil perbaikan dataset kita dari diagram pencar yang baru berikut.
# Membuat diagram pencar antara variabel jarak dan biaya transportasi sepekan
# untuk mahasiswa yang pakai layanan online, setelah pencilan dihilangkan
scp <- ggplot(
data = data_mahasiswa_online,
mapping = aes(
x = jarak, # variabel di sumbu X
y = `biaya sepekan`
)
) + # variabel di sumbu Y
geom_point(
color = "navy", # mengatur warna titik
alpha = 0.2, # mengatur transparansi
size = 1.5, # mengatur ukuran titik
shape = 15
) + # mengatur bentuk titik menjadi persegi
labs(
title = "Jarak tempat tinggal vs. Biaya Transportasi Sepekan",
subtitle = "Mahasiswa dengan Moda Transportasi Layanan Online",
y = "Biaya transportasi sepekan (ribu rupiah)",
x = "Jarak dari tempat tinggal ke kampus (km)"
)
# Menampilkan diagram yang baru
scp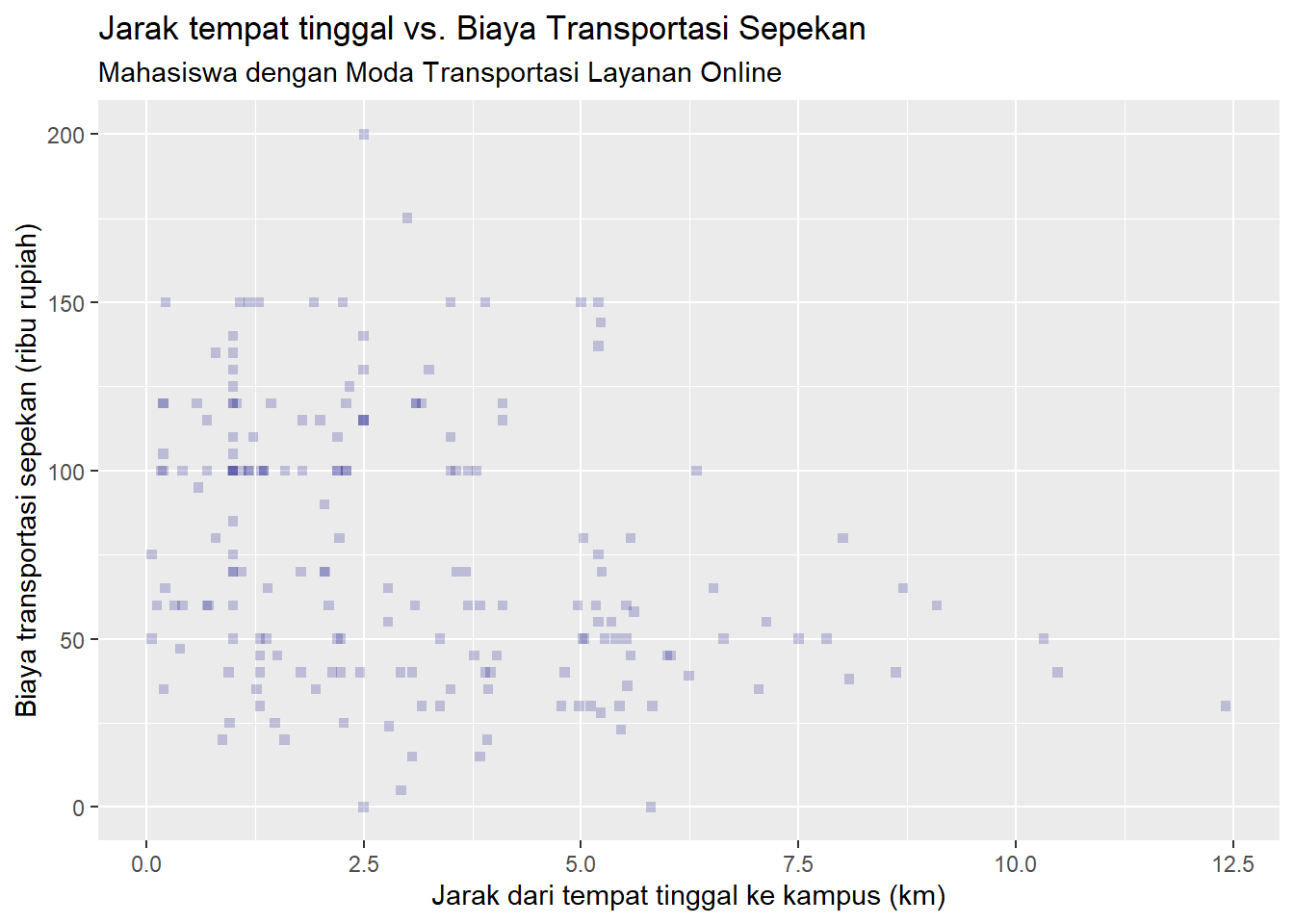
9.6 Model Regresi Linear Sederhana
Dalam bagian ini kita akan mempelajari cara menyusun, menampilkan, menafsirkan/menginterpretasi, dan memprediksi nilai variabel dependen berdasarkan model yang kita susun.
9.6.1 Penyusunan Model
Untuk membuat persamaan model regresi linear, kita akan menggunakan perintah lm() yang sudah disediakan secara bawaan oleh R. Hasil dari perintah ini dapat kita simpan sebagai variabel tertentu.
# Membuat model regresi linear
model <- lm(y ~ x, data = data_mahasiswa_online)Argumen yang kita gunakan adalah var_dependen ~ var_independen serta nama dataset yang kita gunakan. Tanda ~ (disebut tilde) dapat kita masukkan dengan menekan Shift + ` yang ada di sebelah kiri tombol angka 1 di keyboard kita.
Sebelumnya kita sudah mendefinisikan y dan x sebagai variabel untuk vektor biaya transportasi sepekan dan vektor jarak, sehingga kita bisa langsung menggunakannya di atas. Dataset yang kita gunakan adalah dataset mahasiswa yang menggunakan layanan online sebagai moda transportasi utama yang kita simpan dalam data_mahasiswa_online.
Aktivitas Mandiri 3
Definisikan model tersebut dan jawablah:
- Berdasarkan jumlah variabel independen dan dependennya, apa nama jenis analisis regresi linear ini?
- Variabel manakah yang menjadi variabel dependen dan independen?
9.6.2 Penampilan Model
Untuk menampilkan hasil penyusunan model regresi linear, kita akan menggunakan perintah summary yang juga sudah disediakan secara bawaan oleh R.
# Menampilkan hasil model regresi linear
summary(model)
##
## Call:
## lm(formula = y ~ x, data = data_mahasiswa_online)
##
## Residuals:
## Min 1Q Median 3Q Max
## -79.255 -30.717 -3.562 26.758 120.787
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 92.557 4.598 20.129 < 2e-16 ***
## x -5.321 1.205 -4.414 1.72e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 38.11 on 185 degrees of freedom
## Multiple R-squared: 0.09528, Adjusted R-squared: 0.09039
## F-statistic: 19.48 on 1 and 185 DF, p-value: 1.721e-05Yang ditampilkan dengan perintah tersebut antara lain adalah sebagai berikut.
-
Call: bentuk persamaan model yang sudah kita input sebelumnya -
Residuals: informasi residual model -
Coefficients: tabel yang menunjukkan angka-angka dalam persamaan model yang dihasilkan - Nilai-nilai uji kualitas model seperti
Residual standard error(standard error estimasi), Multiple R-squared dan Adjusted R-squared (koefisien determinasi), serta F-statistic (uji signifikansi model).
Penjelasan lebih detil akan diberikan di subbagian selanjutnya.
Selain menggunakan summary, kita juga dapat menggunakan perintah tbl_regression, perintah yang disediakan oleh paket/library gtsummary. Hasil dari perintah ini adalah tabel yang sudah diformat sesuai dengan templat artikel ilmiah.
# Menampilkan hasil model regresi linear dengan tbl_regression
tbl_regression(model)| Characteristic | Beta | 95% CI | p-value |
|---|---|---|---|
| x | -5.3 | -7.7, -2.9 | <0.001 |
| Abbreviation: CI = Confidence Interval | |||
Secara bawaan, tabel tidak menampilkan nilai konstanta (intercept), menampilkan nilai confidence level 95%, dan menampilkan nilai dari variabel independen sesuai variabel yang kita tetapkan sebelumnya, dalam hal ini adalah x. Untuk menggantinya, kita dapat melakukan penyesuaian perintah sebagai berikut.
tbl_regression(
model,
# mengatur intercept-nya ditampilkan
intercept = TRUE,
# mengatur nilai confidence level menjadi 99%
conf.level = 0.99,
# Mengganti tulisan "x" saja menjadi yang lebih bermakna
label = list(x ~ "Jarak tempuh ke kampus, km")
)| Characteristic | Beta | 99% CI | p-value |
|---|---|---|---|
| (Intercept) | 93 | 81, 105 | <0.001 |
| Jarak tempuh ke kampus, km | -5.3 | -8.5, -2.2 | <0.001 |
| Abbreviation: CI = Confidence Interval | |||
9.6.3 Penafsiran/interpretasi Model
Yang kita akan tafsirkan dari model kita di antaranya adalah:
- persamaan model
- makna nilai konstanta dan koefisien
- uji kualitas model (ANOVA,
F-statistic)
9.6.3.1 Tafsiran persamaan model
Persamaan model dapat kita tafsirkan berdasarkan keluaran dari perintah coef(model).
# Membuat nilai koefisien model regresi linear sederhana
koef_simple <- coef(model)
# Menampilkan koefisien variabel model regresi linear sederhana
koef_simpleHasil fungsi tersebut juga dapat kita temukan pada;
-
Coefficientsdarisummary(model)atau -
tbl_regression(model).
Perintah coef() menghasilkan vektor yang menyimpan nilai intercept dan koefisien dari variabel independen. Ini sama saja dengan nilai-nilai di bawah kolom Estimate pada keluaran perintah summary() atau nilai-nilai di bawah kolom Beta pada keluaran tbl_regression().
Berdasarkan keluaran-keluaran perintah tersebut, kita dapat mengetahui bagaimana persamaan regresi linearnya dengan mengganti \(\beta_0\) dan \(\beta_1\) pada bentuk umum persamaan regresi linear dengan angka-angka pada koef_simple.
Bentuk umum:
\[ y = \beta_0 + \beta_1x \]
seperti halnya yang sudah kita pelajari:
- \(\beta_0\) adalah konstanta
- \(\beta_1\) adalah koefisien
Untuk menampilkan nilai intercept dan koefisien variabel independen dari variabel koefisien koef_simple yang sudah kita buat, kita hanya tinggal mengakses elemen-elemen vektor tersebut seperti berikut.
# Menampilkan nilai intercept
koef_simple[1]
cat("----------\n")
# Menampilkan nilai koefisien untuk x (jarak)
koef_simple[2]## (Intercept)
## 92.55684
## ----------
## x
## -5.320761Aktivitas Mandiri 4
Tuliskan persamaan model tersebut dengan perintah cat() seperti berikut dan gantilah ... dengan angka yang tepat untuk memanggil konstanta (intercept) dan koefisiennya. Hasilnya adalah pernyataan seperti berikut.
## Persamaan model dari biaya sepekan terhadap jarak adalah y = 92.55684 + -5.320761 x
cat(
"Persamaan model dari biaya sepekan terhadap jarak adalah",
"y = ", koef_simple[...], " + ", koef_simple[...], "x"
)Dari persamaan model ini kita dapat menggambar garis yang melewati titik-titik data kita. Ini merupakan persamaan garis terbaik dari seluruh kemungkinan persamaan garis yang ada, yang kita tentukan dengan meminimalkan kuadrat terkecil.
# Membuat diagram pencar antara variabel jarak dan biaya transportasi sepekan
# untuk mahasiswa yang pakai layanan online, setelah pencilan dihilangkan,
# ditambah garis dari persamaan regresi
scp <- ggplot(
data = data_mahasiswa_online,
mapping = aes(
x = jarak, # variabel di sumbu X
y = `biaya sepekan`
)
) + # variabel di sumbu Y
geom_point(
color = "navy",
alpha = 0.2,
size = 1.5,
shape = 15
) +
geom_abline(aes(
# ingat bahwa ini memanggil elemen pertama dari vektor 'koef'
# yang merupakan nilai koefisien/intercept
intercept = koef_simple[1],
# sementara itu, elemen kedua dari vektor 'koef' adalah nilai koefisien
# variabel independen kita
slope = koef_simple[2],
color = "red"
)) +
labs(
title = "Jarak tempat tinggal vs. Biaya Transportasi Sepekan",
subtitle = "Mahasiswa dengan Moda Transportasi Layanan Online",
y = "Biaya transportasi sepekan (ribu rupiah)",
x = "Jarak dari tempat tinggal ke kampus (km)"
)
# Menampilkan diagram pencar
scp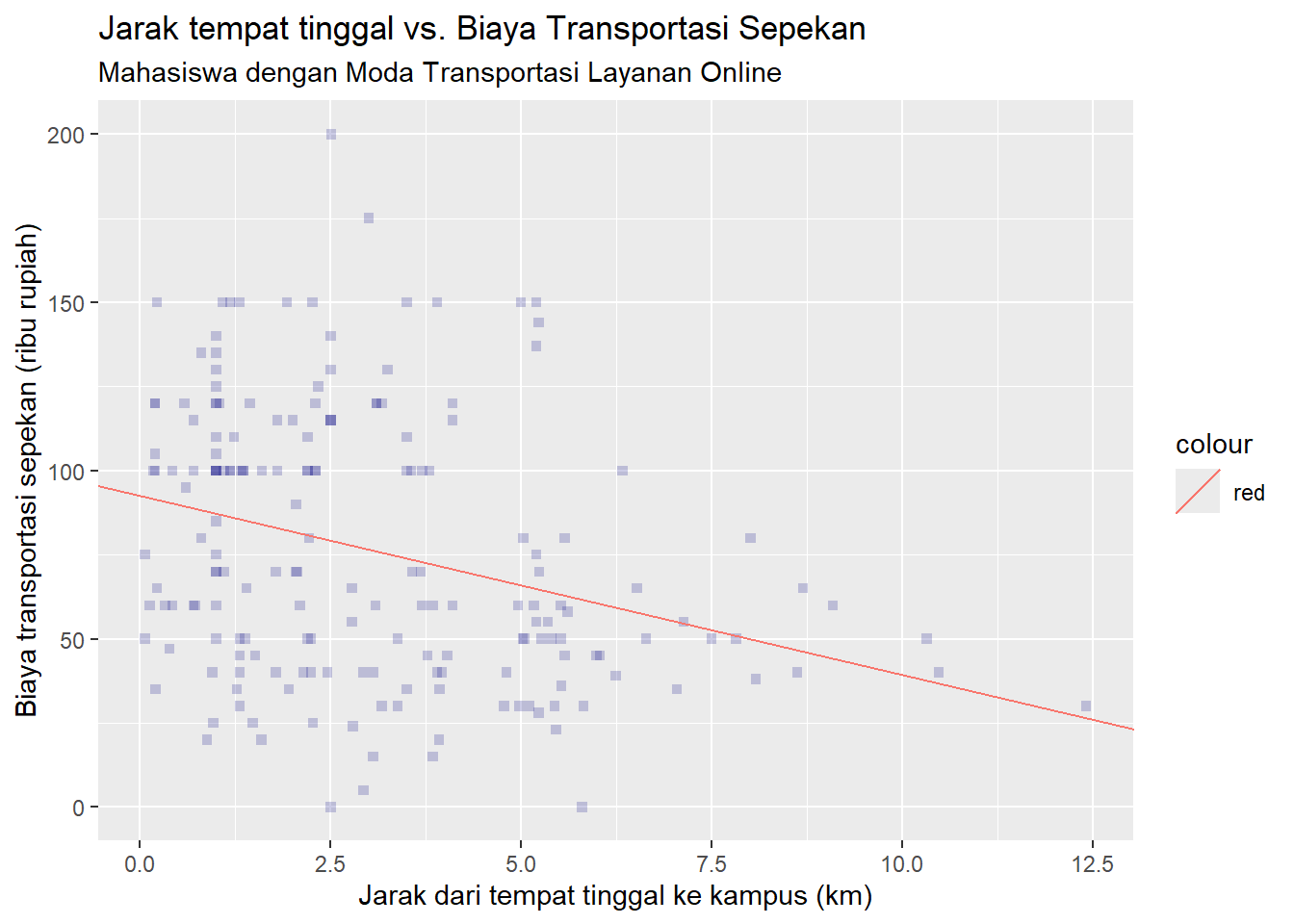
koef[1]mengacu pada elemen pertama dari vektorkoefyang menyimpan nilai intercept/konstanta. Ini menjadi nilai dari atributinterceptyang terletak dalam fungsigeom_ablinekoef[2]mengacu pada elemen kedua dari vektorkoefyang menyimpan nilai koefisien variabel independen kita. Ini menjadi nilai dari atributslopeyang terletak dalam fungsigeom_ablinekarena nilai koefisien variabel independen menunjukkan kemiringan garis persamaan regresi linear kita
9.6.3.2 Tafsiran nilai konstanta dan koefisien
Nilai konstanta berarti bahwa dengan tinggal di kampus (\(x=0\)), mahasiswa masih akan mengeluarkan biaya sebesar koef_simple[1] \(\times 1000\) rupiah (ingat bahwa variabel biaya sepekan menggunakan satuan ribuan rupiah) untuk mengakses kampus selama sepekan. Kita bisa pahami hal tersebut sebagai perkiraan biaya perjalanan mahasiswa yang tinggal di asrama, misalnya.
Sementara itu, nilai koefisien sebesar koef_simple[2] berarti bahwa penambahan jarak sebesar 1 km akan mengurangi biaya transportasi sepekan sebesar koef_simple[2]\(\times 1000\) rupiah. Artinya, makin jauh 1 km seorang mahasiswa tinggal dari kampus, makin kecil pula biaya transportasi sepekannya sebesar koef_simple[2]\(\times 1000\) rupiah.
Nilai koefisien juga bermakna besar gradien garis persamaan regresi linear kita yang mencerminkan kemiringan garis persamaan regresi linear tersebut. Semakin besar nilai koefisien, semakin curam garis persamaan regresi linear kita.
Pertanyaan Bonus
Mengapa mahasiswa yang tinggal lebih jauh dari kampus biaya perjalanan sepekannya lebih kecil? Bukankah biaya transportasi, apalagi transportasi daring, makin jauh malah makin mahal? Apa kira-kira penyebab kecilnya biaya perjalanan tersebut?
9.6.3.3 Tafsiran uji kualitas model
Mari kita panggil kembali ringkasan model kita dengan perintah summary():
# Menampilkan ringkasan model
summary(model)
##
## Call:
## lm(formula = y ~ x, data = data_mahasiswa_online)
##
## Residuals:
## Min 1Q Median 3Q Max
## -79.255 -30.717 -3.562 26.758 120.787
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 92.557 4.598 20.129 < 2e-16 ***
## x -5.321 1.205 -4.414 1.72e-05 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 38.11 on 185 degrees of freedom
## Multiple R-squared: 0.09528, Adjusted R-squared: 0.09039
## F-statistic: 19.48 on 1 and 185 DF, p-value: 1.721e-05Uji kualitas model kita terdiri atas standard error dari residual (Residual standard error), koefisien determinasi atau \(R^2\) (Multiple R-squared), dan uji signifikansi persamaan menggunakan statistik \(F\) (F-statistic) yang merupakan hasil ANOVA (analysis of variance).
Residual standard erroradalah standard error dari residual yang mencerminkan nilai rata-rata galat (residu), yaitu selisih nilai variabel dependen yang dihitung (biaya perjalanan sepekan hasil prediksi dari model) dengan nilai variabel dependen yang kita peroleh dari data.-
Multiple R-squaredadalah koefisien determinasi atau \(R^2\) yang menyatakan keakuratan prediksi dari model kita, yang angkanya bermakna seberapa banyak proporsi variansi data variabel dependen kita (biaya perjalanan sepekan) dijelaskan oleh variabel independennya (jarak dari kampus ke tempat tinggal). Makin tinggi nilai \(R^2\) dari model kita, makin tinggi daya penjelas dari variabel independen kita terhadap data variabel dependen. Dengan kata lain, \(R^2\) menjawab pertanyaan “seberapa kuat model mampu menerka variasi pada variabel dependen?”Sisa dari angka \(R^2\) ini adalah banyak variansi yang tidak dijelaskan oleh variabel independen, artinya dijelaskan oleh variabel lainnya yang tidak ada dalam model dan juga keacakan (misal dalam pengambilan data atau kejadian acak).
F-statisticsadalah uji hipotesis ANOVA (analysis of variance) yang membuktikan hipotesis nol bahwa tidak ada hubungan antara variabel dependen dengan variabel independen secara statistik yang kita modelkan. Kegagalan menolak hipotesis nol ini ditandai dari nilai signifikansi (p-value) yang lebih kecil dari 5% (0.05). Jika demikian, penjelasan variabel dependen oleh variabel independen hanya terjadi secara kebetulan di sampel kita, tidak bisa disimpulkan berlaku pada populasi. Sebaliknya, jika hipotesis nol ditolak, maka penjelasan variabel dependen oleh variabel independen signifikan secara statistik dan bisa disimpulkan berlaku pada populasi.
Aktivitas Mandiri 5
Jawablah pertanyaan-pertanyaan berikut untuk membantu Anda menafsirkan model yang telah dibuat:
- Nilai
Residual standard errorharus dikalikan dengan 1000 terlebih dahulu untuk mengetahui rata-rata galat antara biaya perjalanan dari data yang sebenarnya, untuk para pengguna angkutan daring, dengan hasil perhitungan model. Berapakah besar galat biaya perjalanan sepekan antara data dengan hasi perhitungan? - Berapa persen variansi biaya perjalanan sepekan untuk para pengguna angkutan daring yang dijelaskan oleh variansi jarak perjalanan ke kampus?
- Apakah penjelasan variabel jarak perjalanan ke kampus terhadap biaya perjalanan sepekan untuk pengguna transportasi daring hanya terjadi secara kebetulan di sampel kita?
9.6.4 Melakukan Prediksi
Kita melakukan prediksi dengan menggunakan perintah predict. Perintah ini mengambil masukan berupa model yang kita buat dan sebuah data frame atau tibble.
Perintah berikut adalah untuk melakukan prediksi biaya perjalanan sepekan untuk mahasiswa pengguna transportasi daring yang tinggal di jarak 90 dan 120 dari kampus.
## 1 2
## -386.3117 -545.9345- Perintah
tibbleadalah perintah untuk membuat tibble berisi kolom bernamaxyang terdiri atas nilai 90 dan 120 km, sesuai yang ditentukan sebelumnya. Kita menyimpan tibble tersebut ke dalam variabel bernamabahan_pred - Dalam membuat dataset untuk prediksi kita harus memperhatikan nama variabel/nama kolom yang kita berikan dalam perintah
tibble(). Nama kolom yang akan kita prediksi harus sama persis dengan nama variabel yang kita nyatakan dalam perintahlm.
9.7 Model Regresi Linear Berganda
9.7.1 Persiapan Data
Dalam bagian ini kita hanya akan mempelajari penggunaan variabel dummy untuk meningkatkan kekuatan prediksi kita. Di akhir, Anda akan menafsirkan hal-hal yang sudah Anda pelajari pada bagian regresi linear.
Kita akan menggunakan variabel jenis tempat tinggal untuk variabel dummy. Pertama, kita akan mengatur jenis nilai pada kolom jenis tempat tinggal menggunakan perintah factor.
# Membuat nilai kolom menjadi variabel kategoris dengan 'factor'
data_mahasiswa_online$`jenis tempat tinggal` <- factor(data_mahasiswa_online$`jenis tempat tinggal`)9.7.2 Penyusunan model
Kedua, kita akan membuat model seperti halnya yang kita lakukan dalam analisis regresi linear sederhana. Kita akan menggunakan nama yang lebih representatif untuk variabel-variabelnya.
# Membuat variabel-variabel
jarak <- x # variabel 'x' saja diubah menjadi 'jarak'
biaya <- y # variabel 'y' saja diubah menjadi 'biaya'
ling <- data_mahasiswa_online$`jenis tempat tinggal` # tempat tinggal diberi
# nama 'ling'
# Menyatakan model
mdl <- lm(biaya ~ jarak + ling, data = data_mahasiswa_online)
# Melihat hasil pemodelan
summary(mdl)
##
## Call:
## lm(formula = biaya ~ jarak + ling, data = data_mahasiswa_online)
##
## Residuals:
## Min 1Q Median 3Q Max
## -73.743 -23.421 -2.143 19.424 114.322
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 98.103 8.104 12.105 < 2e-16 ***
## jarak -4.954 1.118 -4.431 1.63e-05 ***
## lingKos sendiri -20.779 8.787 -2.365 0.0191 *
## lingRumah mengontrak bersama -17.198 10.409 -1.652 0.1002
## lingRumah mengontrak pribadi 27.744 16.031 1.731 0.0852 .
## lingRumah pribadi 20.348 9.866 2.062 0.0406 *
## lingRumah saudara 10.365 12.689 0.817 0.4151
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 34.23 on 180 degrees of freedom
## Multiple R-squared: 0.2899, Adjusted R-squared: 0.2663
## F-statistic: 12.25 on 6 and 180 DF, p-value: 1.538e-11Selanjutnya, kita akan menafsirkan hasil dari summary model ini.
9.7.3 Penjelasan Variabel Dummy
Dalam persamaan model kita tersebut, variabel ling atau jenis tempat tinggal diubah menjadi variabel dummy :
-
lingKos sendiri, -
lingRumah mengontrak bersama, -
lingRumah mengontrak pribadi, -
lingRumah pribadi, dan -
lingRumah saudara.
Nama variabel-variabel tersebut tak lain adalah gabungan kata ling dengan tiap-tiap kategori dalam variabel jenis tempat tinggal.
Perhatikan bahwa kita jadi memiliki 5 variabel dummy dari satu variabel kategoris jenis tempat tinggal yang terdiri atas 6 kategori nilai: Kos bersama-sama, Kos sendiri, Rumah mengontrak bersama, Rumah mengontrak pribadi, Rumah pribadi, dan Rumah saudara.
Variabel dummy adalah variabel yang hanya bernilai 0 (nol) atau 1 (satu). Nilai 0 berarti variabel dummy tersebut bernilai “salah” atau “tidak”, sedangkan nilai 1 berarti variabel dummy tersebut bernilai “benar” atau “ya.”
Variabel-variabel dummy yang 5 buah ini hanya akan bernilai 1 atau 0 sesuai dengan kategori dari variabel jenis tempat tinggal suatu objek. Perhatikan bahwa kita tidak punya “lingKos bersama-sama” dalam variabel dummy kita. Ini artinya apabila kategori jenis tempat tinggal suatu objek adalah “Kos bersama-sama”, kelima variabel dummy akan bernilai 0.
Tabel berikut merangkum nilai-nilai variabel dummy untuk setiap kategori nilai variabel jenis tempat tinggal.
| Kategori | lingKos_sendiri | lingRumah_mengontrak_bersama | lingRumah_mengontrak_pribadi | lingRumah_pribadi | lingRumah_saudara |
|---|---|---|---|---|---|
| Kos sendiri | 1 | 0 | 0 | 0 | 0 |
| Rumah mengontrak bersama | 0 | 1 | 0 | 0 | 0 |
| Rumah mengontrak pribadi | 0 | 0 | 1 | 0 | 0 |
| Rumah pribadi | 0 | 0 | 0 | 1 | 0 |
| Rumah saudara | 0 | 0 | 0 | 0 | 1 |
| Kos bersama-sama | 0 | 0 | 0 | 0 | 0 |
9.7.4 Interpretasi Variabel Dummy
Dalam menginterpretasi variable dummy kita tidak bisa menggunakan Pr(>|t|) semata, karena variabel dummy pada hakikatnya sepaket. Jadi, walaupun nilai Pr(>|t|) sebuah variabel dummy adalah >0,05 ia akan tetap berada dalam persamaan regresi linear.
Interpretasi koefisien variabel dummy adalah dengan memahami bahwa nilai variabel dependen berubah sesuai nilai koefisien apabila variabel dummy tersebut bernilai benar atau 1. Artinya, jika mahasiswa tinggal di kosan sendirian (lingKos sendiri = 1), maka biaya transportasi sepekan berkurang sebesar 20.779 yang juga berarti sebesar 20,7 ribu rupiah. Jika mahasiswa tinggal di rumah pribadi (lingRumah pribadi = 1) maka biaya transportasi sepekan bertambah sebesar 20.348 atau 20,3 ribu rupiah.
9.7.5 Penafsiran Model
Seperti halnya pada regresi linear sederhana, yang akan kita tafsirkan dari model kita di antaranya:
- persamaan model
- makna nilai konstanta dan koefisien
- uji kualitas model (ANOVA,
F-statistic), dan ditambah dengan, khusus untuk regresi linear berganda, uji kualitas variabel (Pr(>|t|))
9.7.5.1 Persamaan model
Masih sama seperti pada regresi linear sederhana, perintah untuk menampilkan koefisien & konstanta pada persamaan regresi linear berganda adalah coef().
# Menyimpan koefisien model regresi linear berganda
koef_mult <- coef(mdl)
# Menampilkan koefisien model regresi linear berganda
koef_mult## (Intercept) jarak
## 98.103039 -4.954165
## lingKos sendiri lingRumah mengontrak bersama
## -20.778944 -17.197766
## lingRumah mengontrak pribadi lingRumah pribadi
## 27.744112 20.348009
## lingRumah saudara
## 10.364947Seperti yang sudah kita pelajari, persamaan regresi linear berganda pada dasarnya adalah persamaan regresi linear sederhana yang memiliki lebih dari satu variabel independen. Artinya, berdasarkan bentuk umum persamaan regresi linear sederhana, kita cukup menambahkan variabel-variabel independen lainnya beserta koefisiennya ke dalam persamaan.
Kita juga dapat menggunakan penamaan variabel lain selain x dan y untuk memudahkan interpretasi. Untuk kasus ini, kita bisa menggunakan kata \(biaya\) untuk menggantikan \(y\), \(jarak\) untuk menggantikan \(x_1\), \(lingKos\_sendiri\) untuk menggantikan \(x_2\), dan seterusnya.
Aktivitas Mandiri 7
Tuliskan persamaan model tersebut dengan perintah cat() seperti berikut dan gantilah ... dengan angka yang tepat untuk memanggil konstanta (intercept) dan koefisien-koefisiennya. Hasilnya adalah pernyataan seperti berikut.
## Persamaan model dari biaya sepekan terhadap jarak adalah y = 98.10304 + -4.954165 jarak + -20.77894 lingKos_sendiri + -17.19777 lingRumah_mengontrak_bersama + 27.74411 lingRumah_mengontrak_pribadi + 20.34801 lingRumah_pribadi + 10.36495 lingRumah_saudara
cat(
"Persamaan model dari biaya sepekan terhadap jarak adalah",
"y = ", koef_mult[...], " + ",
koef_mult[...], "jarak +",
koef_mult[...], "lingKos_sendiri +",
koef_mult[...], "lingRumah_mengontrak_bersama +",
koef_mult[...], "lingRumah_mengontrak_pribadi +",
koef_mult[...], "lingRumah_pribadi +",
koef_mult[...], "lingRumah_saudara"
)9.7.5.2 Tafsiran Nilai Konstanta dan Koefisien
Untuk persamaan linear berganda, kita tidak hanya mempertimbangkan pengaruh satu variabel independen seperti halnya pada regresi linear sederhana. Dengan adanya variabel independen lain, maka kita bisa menghitung pengaruh variabel independen lain tersebut secara bersamaan.
Dalam kasus ini, penambahan \(jarak\) sebanyak 1 km akan meningkatkan biaya perjalanan sepekan mahasiswa sebesar koef_mult[2] \(\times 1000\) rupiah, dengan asumsi variabel-variabel \(ling...\) tetap. Jika variabel-variabel dummy \(ling...\) berubah, kita bisa langsung menghitungnya juga.
Untuk variabel dummy, dalam kasus ini variabel \(lingKos\_sendiri\), \(lingRumah\_mengontrak\_bersama\), dan seterusnya, biaya perjalanan sepekan akan berubah jika variabelnya bernilai 1. Misalnya, jika mahasiswa tinggal di Rumah saudara, maka nilai variabel \(lingRumah\_saudara = 1\) sementara yang lain 0. Pengaruhnya adalah biaya perjalanan sepekan berubah sebesar koef_mult[7] \(\times 1000\) rupiah, sesuai koefisiennya.
9.7.5.3 Tafsiran Uji Kualitas Model
Sama seperti regresi sederhana, kita panggil ringkasan model berganda kita dengan summary():
# Menampilkan ringkasan model berganda
summary(mdl)
##
## Call:
## lm(formula = biaya ~ jarak + ling, data = data_mahasiswa_online)
##
## Residuals:
## Min 1Q Median 3Q Max
## -73.743 -23.421 -2.143 19.424 114.322
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 98.103 8.104 12.105 < 2e-16 ***
## jarak -4.954 1.118 -4.431 1.63e-05 ***
## lingKos sendiri -20.779 8.787 -2.365 0.0191 *
## lingRumah mengontrak bersama -17.198 10.409 -1.652 0.1002
## lingRumah mengontrak pribadi 27.744 16.031 1.731 0.0852 .
## lingRumah pribadi 20.348 9.866 2.062 0.0406 *
## lingRumah saudara 10.365 12.689 0.817 0.4151
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 34.23 on 180 degrees of freedom
## Multiple R-squared: 0.2899, Adjusted R-squared: 0.2663
## F-statistic: 12.25 on 6 and 180 DF, p-value: 1.538e-11Untuk mengukur seberapa “bagus” model berganda kita, ada tiga hal utama yang perlu kita perhatikan di bagian bawah keluaran tersebut:
-
Residual standard error: Bisa kita bayangkan sebagai “rata-rata melesetnya” prediksi model kita dari data asli. Semakin kecil angkanya, berarti model kita semakin akurat dalam “menebak” biaya perjalanan mahasiswa. -
Adjusted R-squared: Ini adalah “koefisien determinasi yang lebih jujur”. Dalam regresi berganda, nilaiMultiple R-squaredakan selalu naik setiap kali kita menambah variabel baru (meskipun variabel itu tidak penting). Nah,Adjusted R-squaredakan mengoreksi hal ini. Jika kita menambah variabel yang “sampah” atau tidak berguna, nilai ini justru bisa turun. Jadi, gunakan angkaAdjusted R-squareduntuk melihat seberapa besar (%) variansi biaya perjalanan yang bisa dijelaskan oleh kombinasi jarak dan jenis tempat tinggal. -
F-statistic: Ini adalah “lampu hijau” untuk model kita secara keseluruhan. Statistik ini menjawab pertanyaan: “Apakah minimal ada satu saja variabel independen kita (jarak atau tempat tinggal) yang memang punya pengaruh nyata?” Jika nilai signifikansinya (p-value) di bawah 0,05, maka model kita secara keseluruhan dianggap signifikan (bermakna) dan bukan sekadar kebetulan.
9.7.5.4 Tafsiran uji kualitas variabel
Uji kualitas variabel adalah pengujian terhadap signifikansi atau kepentingan variabel independen kita secara individual. Sebagaimana yang telah dijelaskan pada pembahasan Adjusted R-squared di subbab 9.7.5.3, adanya penambahan variabel “sampah” pun akan meningkatkan nilai Multiple R-squared. Untuk mengidentifikasi mana variabel “sampah” tersebut, kita menggunakan pengujian kualitas variabel secara individual ini.
Hasil pengujian kualitas variabel ini diperlihatkan oleh angka p-value dari uji t (t value)-nya, yakni yang ada di kolom Pr(>|t|).
Apabila nilai Pr(>|t|) kita >0,05 maka variabel independen kita dianggap tidak signifikan, karena artinya nilai koefisien yang ada di kolom Estimate sebenarnya adalah nol sehingga bisa dikeluarkan dari persamaan regresi linear.
Sebaliknya, jika nilai Pr(>|t|) kita <0,05 maka variabel independen kita dianggap signifikan, artinya nilai koefisien yang ada di kolom Estimate sebenarnya adalah nilai koefisien tersebut.
Nilai Pr(>|t|) variabel x adalah 1,721e-05 yang berarti koefisien senilai -5.321 adalah signifikan.
Aktivitas Mandiri 8
Gunakan hasil summary(mdl) yang baru saja muncul untuk menjawab teka-teki kualitas model berikut:
- Lihat nilai Adjusted R-squared. Berapa persen variasi biaya perjalanan mahasiswa yang berhasil dijelaskan oleh model berganda ini (jarak + tempat tinggal)? Apakah lebih besar dari model sederhana sebelumnya yang hanya pakai jarak saja?
- Perhatikan bagian paling bawah, yaitu
F-statistic. Apakahp-value-nya masih di bawah 0,05? Apa artinya bagi kebermaknaan model berganda kita di populasi mahasiswa? - Jika Anda harus memilih, mana yang lebih baik digunakan untuk memprediksi biaya perjalanan mahasiswa: model yang hanya melihat jarak saja, atau model yang melihat jarak dan tempat tinggal sekaligus? Mengapa? (Petunjuk: Bandingkan nilai Adjusted R-squared-nya).
- Perhatikan kolom
Pr(>|t|)untuk setiap variabel independen. Variabel mana saja yang signifikan (p-value < 0,05) dan mana yang tidak? - Tuliskan persamaan regresi linear bergandanya sehingga hanya berisi variabel-variabel yang signifikan saja dalam bentuk perintah
cat()seperti berikut:
cat(
"Persamaan model dari biaya sepekan terhadap jarak adalah",
"y = ", koef_mult[...], " + ",
koef_mult[...], "[var_1] +",
koef_mult[...], "[var_2] +",
...
)9.7.6 Prediksi Model
Seperti halnya regresi linear sederhana, dari persamaan model regresi linear berganda kita, kita juga dapat memprediksi nilai biaya perjalanan sepekan untuk mahasiswa-mahasiswa dengan kondisi lain. Misalnya kita ingin memprediksi biaya sepekan transportasi mahasiswa yang tinggal di Rumah saudara berjarak 7,9 km dari kampus dan di Rumah kontrakan bersama yang berjarak 10 km dari kampus.
# Menyusun dataset untuk diprediksi
mhs <- tibble(
jarak = c(7.9, 10),
ling = c("Rumah saudara", "Rumah mengontrak bersama")
)
# melihat hasil prediksi
predict(mdl, mhs)## 1 2
## 69.33008 31.36362